Generative Engine Optimization (GEO) is the practice of structuring content so it gets cited inside an AI-generated answer; SEO structures pages to rank as a clickable link. That one sentence is the whole difference. The hard part is everything underneath it, and that is exactly where most explainers stop.
So this article does not repeat the definition five times. It shows you how a generative engine actually picks, ranks, and quotes a source. How a single prompt gets split into ten searches you never typed. Why brand mentions beat backlinks 3:1. Why "AI traffic" looks invisible in your analytics even when bots are devouring your content. And why the only honest place to measure any of it is your own server logs. The people doing the real reverse-engineering, Resoneo, DEJAN, Botify, SEOmator, are the ones I cite here. Not generic blogs. And the backbone of this piece is our own data, a May 2026 ROI & Shine server-log analysis, set against the field's strongest research.
1. What is the core difference between GEO and SEO? SEO ranks documents, GEO populates answers
Classic SEO is a ranking problem. Google indexes documents, scores each one against the query, and hands back an ordered list. The user clicks. Success means position, get into the top results, win the click.
GEO works on a completely different layer. An AI engine takes your prompt, breaks it apart, fetches a handful of passages, and writes a single answer, usually naming two or three sources along the way. This is RAG: retrieval-augmented generation, where the model fetches passages first and then composes the reply from them. The user often never clicks anything. Here success means citation, getting your words into the answer itself.
This is not "SEO 2.0." It is a different plane with different physics. The cleanest proof: 83% of AI Overview citations come from pages outside the organic top 10, per ConvertMate's 2026 GEO Benchmark (12,500+ queries across 8,000 domains, cross-referenced with BrightEdge and Semrush data). If GEO were just ranking by another name, that number would sit near zero. It does not. The model is not reading a results page, it is reading retrieved passages, and rank barely enters into it.
The numbers that force the rethink
| Signal | Value | Source / method |
|---|---|---|
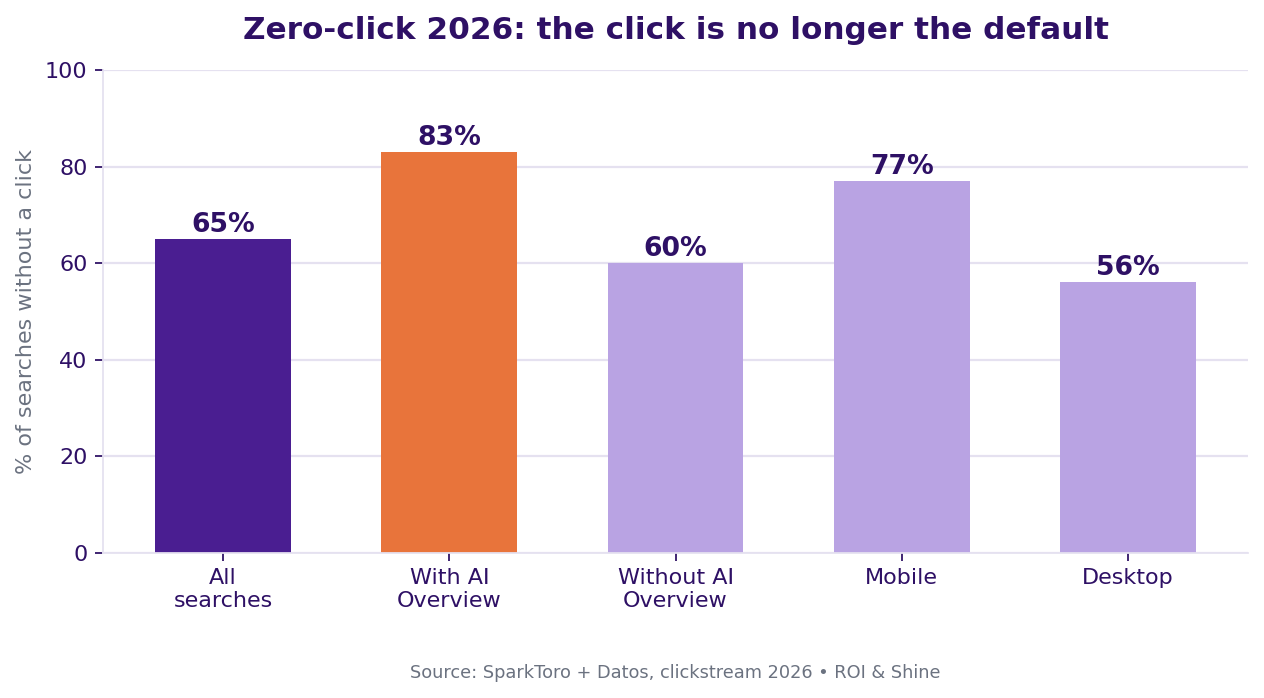
| Zero-click rate (all Google searches) | 64.8% | SparkToro + Datos clickstream study |
| Zero-click rate when an AI Overview appears | ~83% | SparkToro + Datos, AIO-triggered queries |
| Zero-click rate in Google AI Mode | 93% | Nobori analysis, AI Mode at 100M users, 2026 |
| Organic clicks lost on AIO queries (field study) | −38% | ISB + Carnegie Mellon randomized field experiment, Jan to Feb 2026 |
| Zero-click rise in that same study | 54% → 72% | ISB + Carnegie Mellon, two weeks per participant |
One row in that table carries the weight: the field study. It is randomized and causal, not a correlation dredged out of aggregate traffic. AI Overviews cause a 38% drop in clicks on the queries where they show up. They push zero-click, a search that ends with no click, from 54% to 72%. That was measured in an experiment, not inferred after the fact. Zero-click is no longer an edge case. On AI-heavy queries, it is the default.
2. How does an AI engine decide which sources to fetch? Fan-out, web.run, and "site:" gating
Want to optimize for an AI answer? Then you need to know what happens between the prompt and the reply. The sharpest reverse-engineering of that black box comes from Olivier de Segonzac at Resoneo. His "Inside ChatGPT Search" work mapped the web.run tool and the fan-out mechanism, a single prompt split into many sub-queries, that decides which domains ever get fetched.
Three things here matter to anyone doing the work:
- Query fan-out. Your one prompt gets quietly split into 10+ sub-queries, each chasing a different angle or source. Resoneo found GPT-5.4 Thinking spreads its searches across often more than 10 fan-out queries per response. So you are not optimizing for one keyword. You are trying to be the single best passage for one of ten sub-intents the user never actually typed.
site:gating to trusted domains. For some of those sub-queries, the model adds asite:filter and only looks at domains it already trusts. If you are not in that trust set, you are simply invisible there, no matter how good your page is.- Citation compression is volatile. When ChatGPT switched its default from GPT-4o/5.2 to GPT-5.3 Instant on 4 March 2026, the average unique domains cited per response fell from 19 to 15, a >20% drop (Resoneo). One model update can halve your citation footprint overnight, and nobody sends you a memo. Resoneo publishes the reconstructed system prompt, the honeypot experiment, and DIY audit prompts at think.resoneo.com, plus a free Chrome extension that captures the exact fan-out URLs and
ref_ids.
What does this mean in practice? GEO is won at the passage, not the page. The thing that actually wins is a self-contained, quotable, attributable chunk that answers one fan-out sub-query cleanly, not a 3,000-word "pillar page" engineered to rank for a head term.
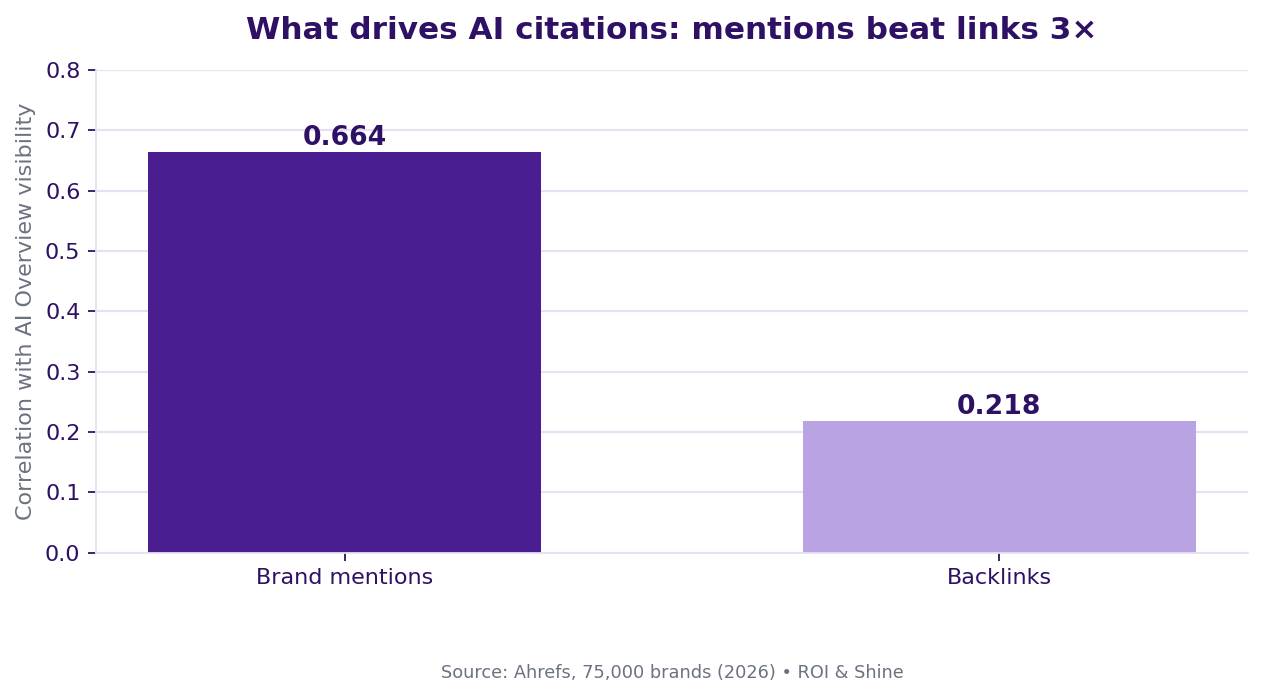
3. Are brand mentions more important than backlinks for AI visibility? Mentions beat links 3:1
The most disruptive number in GEO comes from Ahrefs' analysis of 75,000 brands (August 2025). Brand mentions correlate with AI Overview visibility at 0.664. Backlinks correlate at just 0.218. That is roughly a 3:1 advantage. Branded anchors (0.527) and branded search volume (0.392) came second and third. Backlinks, the thing the whole industry has chased for twenty years, finished near the bottom.
That overturns two decades of link-building doctrine. And the reason makes sense the moment you accept the RAG model. A language model's sense of "who is the authority on X" is not built from a link graph. It is built from how often, and in what context, an entity shows up alongside a topic across the training data. DEJAN's Dan Petrovic formalizes this in his Brand Authority / Language Model Association Networks work. He measures your visibility inside the model using bidirectional entity prompts, and he draws a line between two kinds. Parametric visibility, the model already knows you, the answer comes straight from its trained weights. And grounded visibility, the answer is fetched live from search at the moment of the query. They demand different strategies. You cannot link-build your way into a model's parameters.
There is corroboration from a different angle. Muck Rack's "What Is AI Reading?" analysis of over one million AI-cited links found 82% come from earned media, mentions you earn, not pages you own or ads you buy, with 94% from non-paid sources overall. The pattern is consistent across studies: the citation economy rewards being talked about, not just publishing.
Contrarian take, defensible by data: for AI visibility, one well-placed brand mention in a trusted publication or a busy Reddit thread can outperform a stack of DR-70 backlinks. The 0.664-vs-0.218 gap is not noise. It is a signal to move the budget.
4. Where do AI engines actually pull their sources from? The Reddit problem
If brand mentions are the currency, the next question is obvious: where does the model go to find them? The answer is awkward for anyone still thinking in pure SEO terms.
- Reddit is the single most-cited source across every major AI engine. The 5W AI Platform Citation Source Index 2026 pulled together 680 million+ citations across five AI platforms (ChatGPT, Google AI Overviews, Perplexity, Gemini, Claude, pooled from six published studies). Reddit ranked #1, cited at ~40% frequency across LLMs. The top 15 domains alone soak up ~68% of the entire AI citation pipeline.
- On 7 May 2026, Google launched "Community Perspectives" in AI Overviews, dropping direct quotes from Reddit threads and forums straight into the generated answer (Nobori, CMSWire).
Here is the whole category error in one frame. For SEO, a Reddit thread is a rival fighting you for the same slot. For GEO, a Reddit thread about you is a pipeline straight into the answer. Same thread. Opposite meaning.
5. SEO vs GEO: the comparison table
| Dimension | SEO (classic search) | GEO (generative engines) |
|---|---|---|
| Goal | Rank a page as a clickable link | Be cited / quoted inside the synthesized answer |
| Retrieval model | Index → rank → SERP list | Prompt → fan-out → RAG synthesis |
| Unit of success | Position (top 10) | Citation / inclusion (rank-agnostic) |
| Top signal | Backlinks, on-page relevance | Brand mentions (0.664) > backlinks (0.218) |
| Content atom | The page / pillar | The extractable passage answering one sub-query |
| Where it's won | Your own domain | The whole web, Reddit, earned media, trusted domains |
| Key off-site asset | DR / link graph | Entity co-occurrence, parametric authority |
| Primary tools | GSC, Ahrefs, Semrush, Screaming Frog | Profound, Peec.ai, AthenaHQ + server-log analysis |
| Measurement of truth | Clicks, impressions, rank | Citation share + crawl-to-refer ratio (logs) |
| User behavior | Clicks through to site | 64.8 to 93% zero-click |
| Volatility driver | Algorithm updates | Model version swaps (19→15 domains overnight) |
GEO and SEO are not enemies. Schema, technical health, deep authoritative content, all of it serves both. But the measurement, the content unit, and the off-site play diverge hard. And pretending they are the same thing is exactly how agencies keep selling yesterday's playbook at 2026 prices.
6. Why does AI traffic look invisible in analytics? Crawl-to-refer and the invisible audience
Here is the data that explains the strangest part of all this: your content is clearly being consumed, yet "AI traffic" barely registers in your reports. The reason is blunt. AI engines crawl enormously and refer almost nothing back.
Botify analyzed ~7 billion log files (Nov 2024 to Mar 2026) and found OpenAI tripled its web crawl since GPT-5; GPTBot activity rose 2.9×, a delta of +1.8 billion crawl events. The balance also tilted. The ratio of search events to training events climbed from ~0.95 to ~1.14. In plain terms, OpenAI now spends more of its crawl budget on live web search than on collecting training data.
Then comes the brutal counterpart: the crawl-to-refer ratio, how many pages a bot crawls for every visitor it actually sends you back. Cloudflare put this metric on the map. Cloudflare Radar tracks, per platform, how often each AI crawls a site versus how often it returns a human. The numbers are extreme, and they move around: Cloudflare's own June 2025 snapshot had Anthropic at ~70,900:1; by Q1 2026 the figures below (compiled by SEOmator from Cloudflare Radar) cover a different window.
| Bot | Pages crawled per 1 referral sent (Q1 2026) |
|---|---|
| Anthropic ClaudeBot | 23,951 : 1 |
| OpenAI GPTBot | 1,276 : 1 |
| DuckDuckBot | ~1.5 : 1 |
| Googlebot | ~5 : 1 |
These swing by period, and the gap probably looks worse than it is, traffic from native apps like Claude sends no Referer: header, so some real referrals go uncounted (Cloudflare). But the direction is not in doubt. ClaudeBot's order-of-magnitude ratio is not sloppiness. It is a business model: a pure training crawler with no consumer search product, so there is no place to send anyone back. Step back and the picture is stark, AI crawlers (GPTBot + ClaudeBot + Meta + Amazon + Petal) now account for 51.69% of all crawler traffic, more than every traditional search crawler combined. Meta alone is 36.10% of AI crawl traffic and returns essentially nothing.
So why bother? Because of what the rare referral is worth. AI referral traffic that does land converts at 4.4× the value of traditional organic (ConvertMate / Semrush 2026), with 27% lower bounce and 38% longer sessions. Tiny volume, outsized value. That is the entire GEO investment thesis in one line.
7. How do you actually measure GEO? At the server log, not the dashboard
This is where ROI & Shine draws its line. Most "GEO tools" work by prompting LLMs over and over and tallying how often you get mentioned. Useful, but that is a survey, not ground truth. The only place to see what AI engines genuinely do with your content is your own server logs.
This is not a new conviction for me. I have been running server log-file analysis since 2013, it is the bedrock of serious technical SEO. Back then my SEO team and I built our own log pipeline on Kibana, before dedicated crawler-log tools even existed. Since then I have run log analysis across marketplaces like Machineryzone, Agriaffaires and leboncoin, and e-commerce like expondo, picking up commercial log platforms as the category matured. AI has not changed the rule: every migration and every audit, SEO or GEO, should start at the log. GEO just adds new actors to it. The discipline of reading the log is the same one that has separated real technical SEO from guesswork for over a decade.
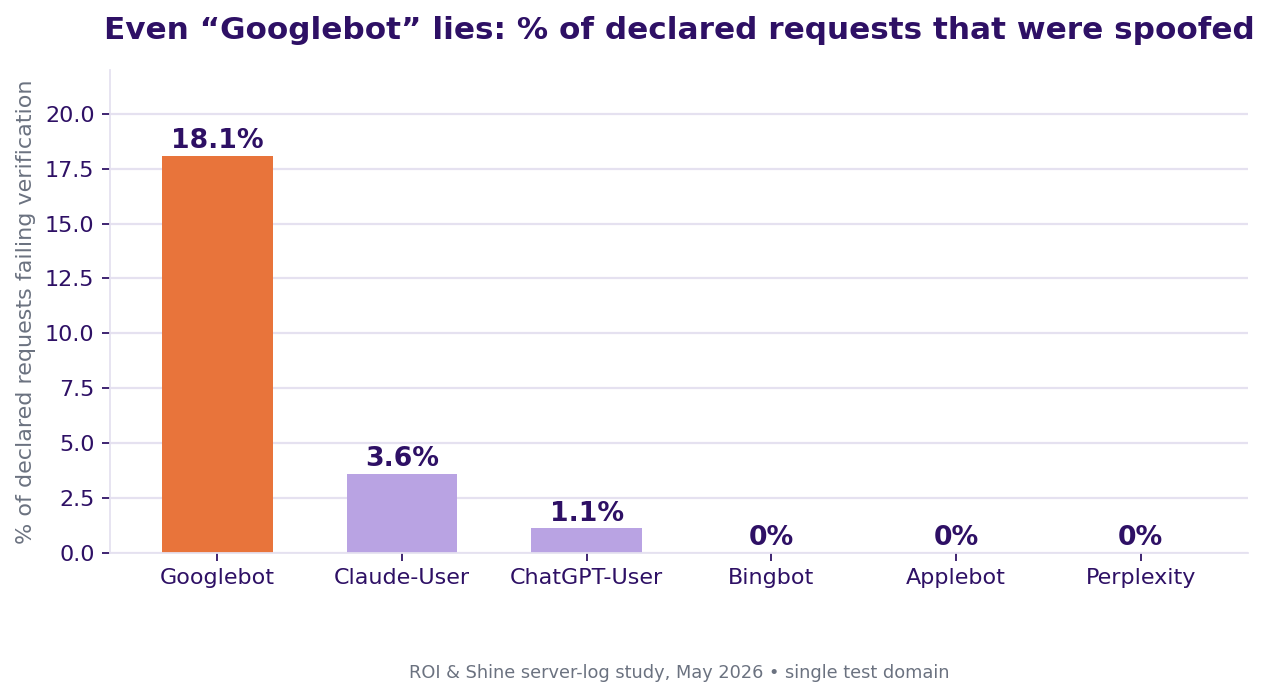
And the logs tell you things no dashboard can. In a May 2026 server-log study we ran at ROI & Shine on one of our own test domains (N=43,345 requests over 26 days, no CDN in front, bot IPs verified against published ranges and forward-confirmed reverse DNS), 4.3% of all declared bot traffic failed verification, and 18% of requests claiming to be Googlebot were spoofed (68 IPs with no valid reverse DNS, many on cheap hosting in RU/UA/DE). Count bots by user-agent and you are counting liars.
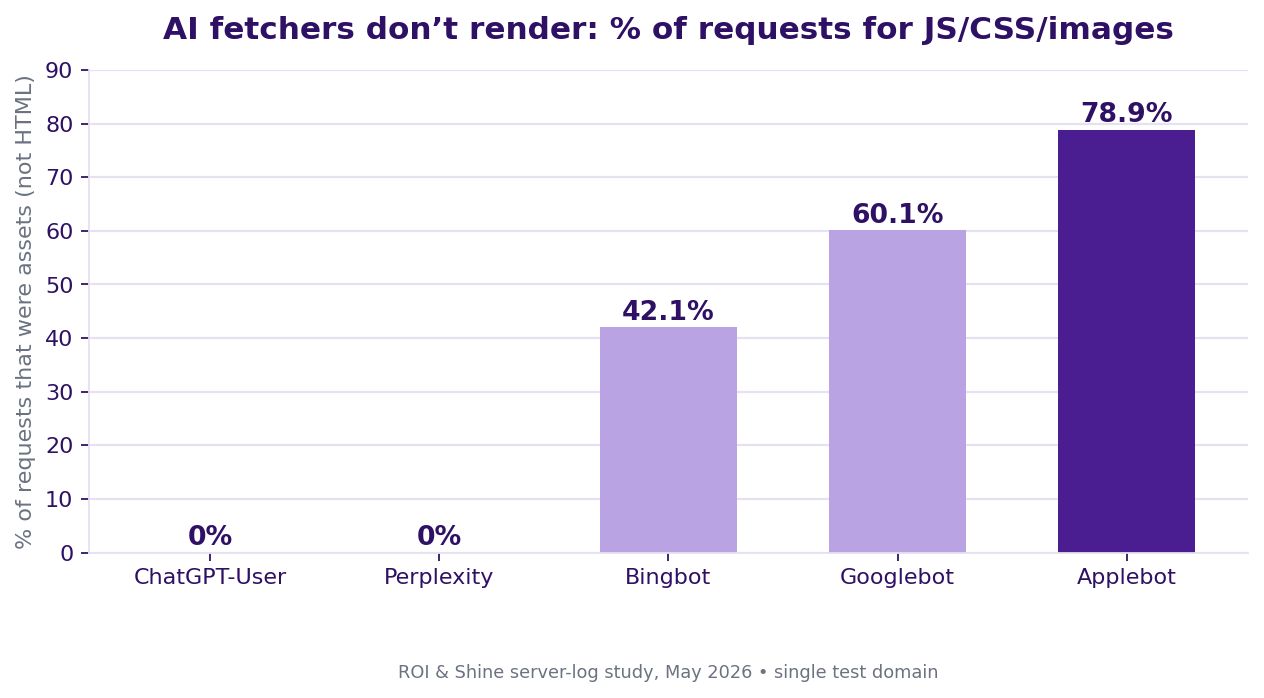
The same logs exposed a second hard rule. The AI fetchers (ChatGPT-User, Perplexity) requested zero JS/CSS/image assets. Googlebot pulled 60%; Applebot pulled 79%. So the AI engines were not running your JavaScript. If your content only appears after client-side JS executes, the fetcher never sees it. Server-side HTML (rendered on the server, not in the browser, SSR/SSG) is not an optimization for AI visibility. It is a precondition.
Log-level measurement answers the questions dashboards simply cannot:
- Which bot is this, and is it even real? You have to separate training crawlers (GPTBot, ClaudeBot) from real-time fetchers (ChatGPT-User, OAI-SearchBot, PerplexityBot); they mean completely different things. And you have to verify the IPs against published ranges, because a big chunk of "GPTBot" traffic is not OpenAI at all.
- *What is your crawl-to-refer ratio?* The benchmark numbers (23,951:1) are averages. Your domain's real ratio, your logs against your AI-referral analytics, is the only figure that actually prices your GEO return.
- Which pages get fetched live during answer generation? A real-time fetcher hitting a URL, lined up against a citation appearing in the answer, is about as close to a causal GEO signal as exists today.
This is precisely the analysis the survey-based tools (Profound, Peec.ai, AthenaHQ) structurally cannot do, they sit outside your server. Tools like Botify, Oncrawl and SEOmator built this discipline for log files. We apply it to GEO attribution.
Coming soon: the full study. The numbers above are a first cut. We are publishing the complete log-file study from one of our own domains: the bot taxonomy, the full spoofing breakdown, the render gap, and our true crawl-to-refer ratio. It lands in our GEO & SEO hub. If a GEO claim can't be traced to a log line, treat it as marketing.
8. One more risk: the model may be inventing its citations
Here is the part most GEO advice skips. AI engines fabricate citations, at rates that should stop you cold. Two 2026 studies make it concrete.
GhostCite (arXiv 2602.06718) tested 13 leading models across 40 domains. Citation-hallucination rates ran from 14.23% to 94.93%, depending on the model and the field.
A second cross-model study (arXiv 2603.07287) checked 17,443 generated citations. No model passed a 0.475 existence rate. In the worst settings, more than half the references pointed to nothing real.
So what does this mean for you? Being named by a model and being correctly cited with a working link are two different outcomes. Strong, unambiguous entity signals, consistent NAP, schema, named brand mentions, lower the odds a model pins your fact on a competitor, or on a source that never existed.
What this means for your 2026 strategy
- Keep the technical SEO (crawlability, schema, Core Web Vitals). Both surfaces stand on it.
- Move off-site budget from raw link volume to brand mentions and earned media. That is the 0.664 signal.
- Write passage-first: self-contained, quotable, attributable chunks that win one fan-out sub-query.
- Earn a presence in community sources, Reddit, forums. They are first-class AI citations now.
- Measure at the server. Separate the bot types, verify the IPs. The dashboard is a survey; the log is the truth.
GEO is not SEO with new keywords. Different layer, different success unit, and, the part most miss, a different measurement plane. The teams that get the difference at the log level are the ones building AI visibility that lasts.
Want this run on your domain? See ROI & Shine's GEO and AEO services, or go deeper in our GEO & SEO hub.