Generative Engine Optimization (GEO) to budowanie treści tak, by AI zacytowało ją wewnątrz swojej odpowiedzi; SEO buduje strony tak, by rankowały jako klikalny link. Tyle wystarczy, by uchwycić różnicę. Ale mechanizm pod spodem to miejsce, w którym większość poradników milknie, a prawdziwa robota dopiero się zaczyna.
Nie będę tu powtarzać definicji pięć razy. Pokażę, jak silnik generatywny wybiera, szereguje i cytuje źródło. Po kolei: fan-out (rozbicie zapytania na podzapytania), sygnał wzmianek o marce, który pobił linki w stosunku 3:1, ekonomia crawl-to-refer (ile stron bot pobiera na jedno odesłanie) tłumacząca, dlaczego „ruch z AI" wydaje się niewidzialny, i wreszcie powód, dla którego jedyne uczciwe miejsce pomiaru GEO to twoje własne logi serwera. Cytuję ludzi, którzy faktycznie rozbierają te silniki na części, Resoneo, DEJAN, Botify, SEOmator, a nie ogólnikowe blogi. A kręgosłupem tego tekstu są nasze własne dane, analiza logów serwera ROI & Shine z maja 2026, zestawione z najlepszymi badaniami rynku.
1. Jaka jest podstawowa różnica między GEO a SEO? SEO szereguje dokumenty, GEO wypełnia odpowiedzi
Klasyczne SEO to problem wyszukiwania i rankingu. Google indeksuje dokumenty, ocenia je względem zapytania i zwraca uporządkowaną listę. Użytkownik klika. Liczy się pozycja.
GEO to zupełnie inna gra, to problem retrieval-augmented generation (RAG), czyli generowania wzbogaconego o pobierane treści. Silnik AI dostaje prompt, rozkłada go na części, pobiera kilka fragmentów i składa z nich jedną odpowiedź. Często cytuje dwa-trzy źródła z nazwy. A użytkownik zwykle w ogóle nie klika. Tu liczy się cytat, ściślej: obecność w zsyntetyzowanym tekście.
To nie jest „SEO 2.0". To inna płaszczyzna wyszukiwania, rządząca się inną fizyką. Najczystszy dowód? 83% cytatów w AI Overviews pochodzi ze stron spoza organicznego top 10, tak wynika z GEO Benchmark 2026 ConvertMate (ponad 12 500 zapytań na 8 000 domen, weryfikowane danymi BrightEdge i Semrush). Gdyby to była ta sama gra co ranking, ta liczba sięgałaby zera. Nie sięga. Bo model nie czyta SERP-a, czyta pobrane fragmenty.
Liczby, które wymuszają przemyślenie
| Sygnał | Wartość | Źródło / metoda |
|---|---|---|
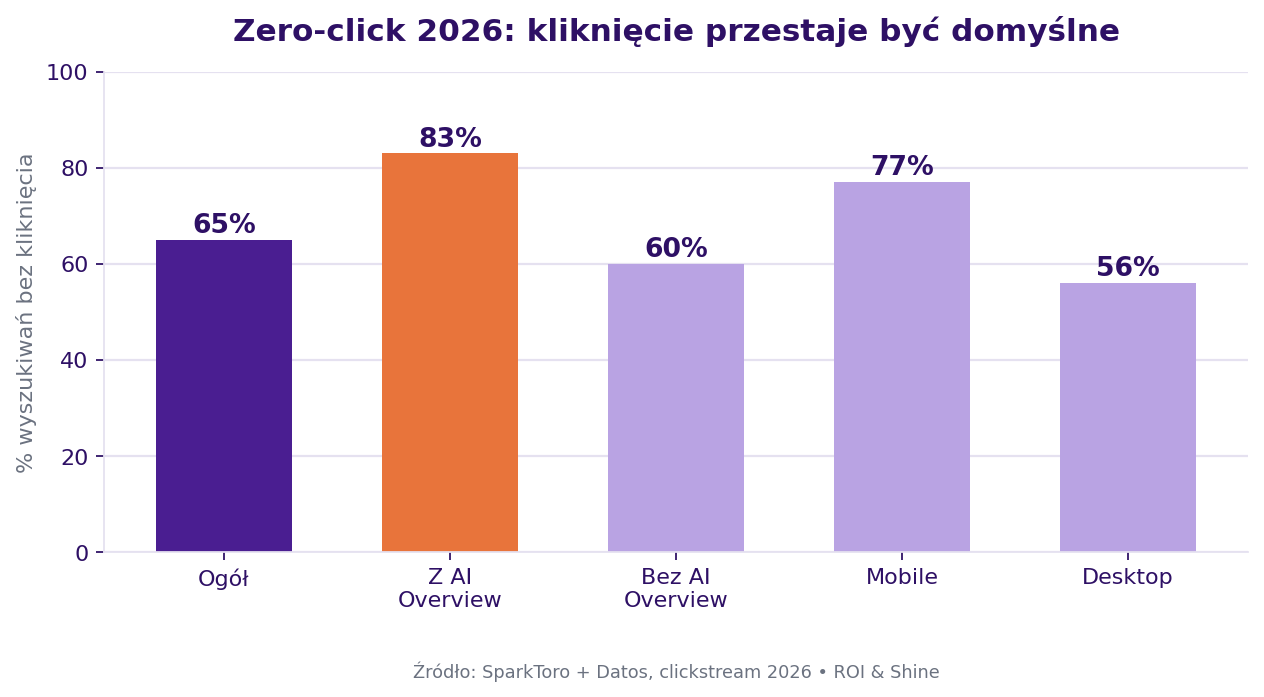
| Zero-click (wszystkie wyszukiwania Google) | 64,8% | SparkToro + Datos, badanie clickstream |
| Zero-click, gdy pojawia się AI Overview | ~83% | SparkToro + Datos, zapytania z AIO |
| Zero-click w Google AI Mode | 93% | Nobori, AI Mode przy 100 mln użytkowników, 2026 |
| Utracone kliknięcia organiczne na zapytaniach z AIO (badanie terenowe) | −38% | Eksperyment ISB + Carnegie Mellon, sty do lut 2026 |
| Wzrost zero-click w tym samym badaniu | 54% → 72% | ISB + Carnegie Mellon, 2 tyg. na uczestnika |
Najważniejsze jest tu badanie terenowe. Bo jest randomizowane i przyczynowe, nie korelacyjne. AI Overviews powodują spadek kliknięć o 38% tam, gdzie się pojawiają, i podbijają zero-click z 54% do 72%. To zmierzono eksperymentalnie, a nie wywnioskowano z ruchu zbiorczego.
2. Jak silnik AI decyduje, które źródła pobrać? Fan-out, web.run i bramkowanie „site:"
Żeby optymalizować pod odpowiedź AI, musisz wiedzieć, co silnik robi pomiędzy promptem a odpowiedzią. Najbardziej rygorystyczny rozbiór tego procesu zrobił Olivier de Segonzac z Resoneo. Jego praca "Inside ChatGPT Search" zmapowała narzędzie web.run i mechanizm fan-out, to on decyduje, które domeny zostaną pobrane.
Trzy rzeczy, które naprawdę powinien znać praktyk:
- Fan-out zapytań. Pojedynczy prompt jest po cichu rozkładany na 10+ podzapytań, każde celuje w inny kąt lub inne źródło. Resoneo ustaliło, że GPT-5.4 Thinking rozprasza wyszukiwania na często ponad 10 zapytań fan-out na jedną odpowiedź. Nie optymalizujesz więc pod jedno słowo kluczowe. Walczysz o to, by być najlepszym fragmentem dla jednego z dziesięciu pod-intentów, których użytkownik nigdy nie wpisał.
- Bramkowanie
site:do zaufanych domen. Model część zapytań fan-out ogranicza operatoremsite:do domen, którym już ufa. Nie ma cię w jego zbiorze zaufania? Jesteś niewidoczny dla tych podzapytań. Niezależnie od jakości strony. - Kompresja cytatów jest niestabilna. 4 marca 2026 ChatGPT przełączył domyślny model z GPT-4o/5.2 na GPT-5.3 Instant. Efekt: średnia liczba unikalnych domen cytowanych na odpowiedź spadła z 19 do 15, spadek o ponad 20% (Resoneo). Jedna aktualizacja modelu potrafi po cichu zmniejszyć twoją obecność w cytatach z dnia na dzień. Resoneo publikuje zrekonstruowany system prompt, eksperyment honeypot i prompty do audytu DIY na think.resoneo.com, a do tego darmowe rozszerzenie Chrome, które przechwytuje dokładne URL-e fan-out i
ref_id.
Wniosek dla praktyka: w GEO wygrywa się na poziomie fragmentu, nie strony. Jednostką atomową jest samodzielny, ekstrahowalny, atrybuowalny kawałek treści, który wygrywa jedno podzapytanie fan-out. Nie strona-filar na 3 000 słów rankująca na frazę główną.
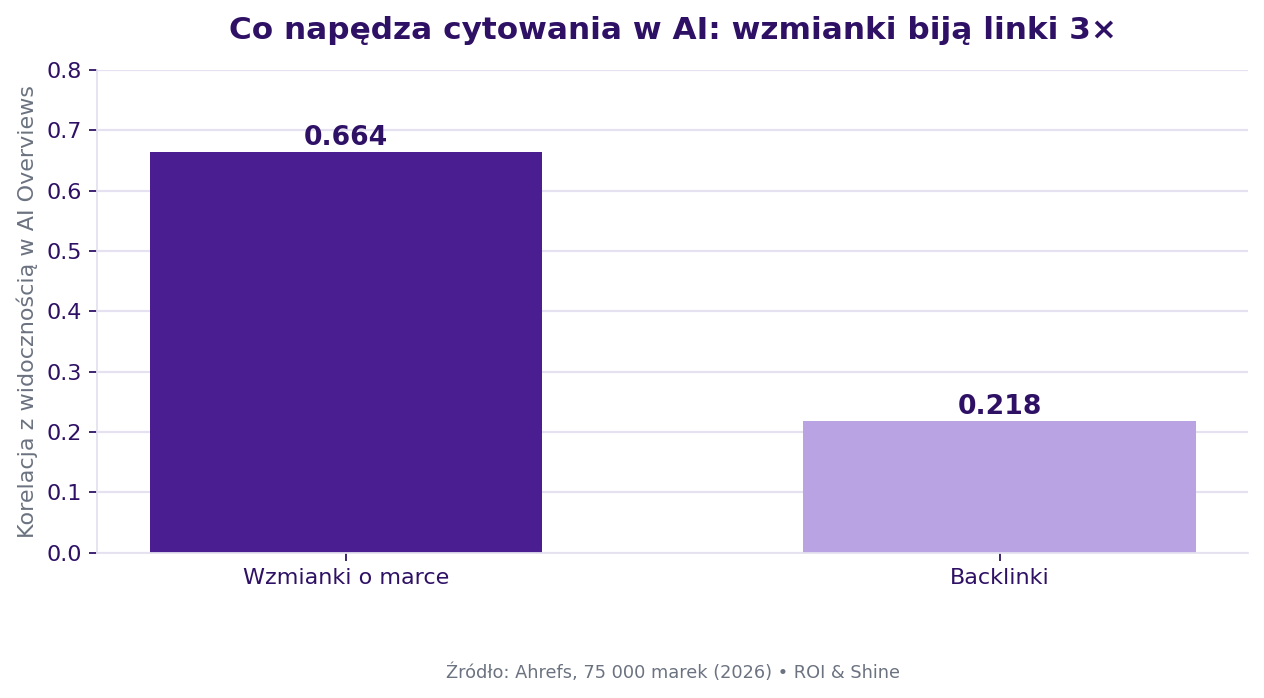
3. Czy wzmianki o marce są ważniejsze niż linki w AI? Wzmianki biją linki 3:1
Najbardziej wywrotowe odkrycie GEO to analiza 75 000 marek przez Ahrefs (sierpień 2025): wzmianki o marce korelują z widocznością w AI Overviews na poziomie 0,664, a linki zaledwie 0,218, przewaga mniej więcej 3:1. Dalej w kolejności: brandowane anchory (0,527) i brandowany wolumen wyszukiwań (0,392).
To wywraca dwadzieścia lat doktryny link-buildingu. A mechanizm jest intuicyjny, gdy przyjmiesz model RAG. Wewnętrzny obraz „kto jest autorytetem w X" buduje się w modelu z tego, jak często i w jakim kontekście dana encja współwystępuje z tematem w korpusie treningowym, nie z grafu linków. Dan Petrovic z DEJAN ujmuje to w ramy w pracy o Brand Authority / Language Model Association Networks. Mierzy widoczność marki wewnątrz modelu dwukierunkowymi promptami encyjnymi. I rozróżnia dwie rzeczy: widoczność parametryczną (odpowiedź płynie z wag treningowych, model już cię „zna") oraz widoczność dynamiczną / ugruntowaną (odpowiedź pobierana na żywo z wyszukiwania). Każda wymaga innej strategii, bo wag modelu nie „dolinkujesz".
Potwierdzenie z drugiej strony: analiza „What Is AI Reading?" Muck Rack na ponad milionie linków cytowanych przez AI pokazała, że 82% pochodzi z earned media (zdobytych wzmianek, nie kupionych), a 94% ze źródeł niepłatnych ogółem, nie ze stron własnych. Ekonomia cytatów nagradza to, że się o tobie mówi. Nie samo publikowanie.
Teza kontrariańska, broniona danymi: dla widoczności w AI jedna dobrze ulokowana wzmianka w zaufanej publikacji albo w popularnym wątku Reddita potrafi przebić paczkę linków z DR-70. Luka 0,664 vs 0,218 to nie błąd zaokrąglenia. To sygnał, żeby przebudować budżet.
4. Skąd silniki AI faktycznie czerpią źródła? Problem Reddita
Skoro wzmianki o marce są walutą, pytanie brzmi: gdzie model je znajduje? Odpowiedź jest niewygodna dla tradycyjnego SEO.
- Reddit to najczęściej cytowane źródło w każdym dużym silniku AI. 5W AI Platform Citation Source Index 2026 zebrał ponad 680 mln cytatów z pięciu platform AI (ChatGPT, Google AI Overviews, Perplexity, Gemini, Claude, z sześciu opublikowanych badań). Reddit zajął #1, cytowany z częstotliwością ~40% w modelach językowych. A 15 najczęstszych domen pochłania ~68% całego pipeline'u cytatów AI.
- 7 maja 2026 Google uruchomił „Community Perspectives" w AI Overviews. Wyświetla bezpośrednie cytaty z wątków Reddita i forów wewnątrz wygenerowanej odpowiedzi (Nobori, CMSWire).
Dla SEO wątek Reddita to konkurent o ten sam slot w SERP-ie. Dla GEO wątek Reddita o tobie to kanał dystrybucji prosto do odpowiedzi. Cały błąd kategorialny w jednym zdaniu.
5. SEO vs GEO: tabela porównawcza
| Wymiar | SEO (klasyczne wyszukiwanie) | GEO (silniki generatywne) |
|---|---|---|
| Cel | Wyrankować stronę jako klikalny link | Być zacytowanym wewnątrz zsyntetyzowanej odpowiedzi |
| Model retrieval | Indeks → ranking → lista SERP | Prompt → fan-out → synteza RAG |
| Jednostka sukcesu | Pozycja (top 10) | Cytat / obecność (niezależnie od rankingu) |
| Najsilniejszy sygnał | Linki, trafność on-page | Wzmianki o marce (0,664) > linki (0,218) |
| Atom treści | Strona / filar | Ekstrahowalny fragment odpowiadający na jedno podzapytanie |
| Gdzie się wygrywa | Twoja domena | Cała sieć, Reddit, earned media, zaufane domeny |
| Kluczowy zasób off-site | DR / graf linków | Współwystępowanie encji, autorytet parametryczny |
| Główne narzędzia | GSC, Ahrefs, Semrush, Screaming Frog | Profound, Peec.ai, AthenaHQ + analiza logów |
| Pomiar prawdy | Kliknięcia, wyświetlenia, pozycja | Udział w cytatach + crawl-to-refer (logi) |
| Zachowanie użytkownika | Klika i wchodzi na stronę | 64,8 do 93% zero-click |
| Źródło zmienności | Aktualizacje algorytmu | Zmiany wersji modelu (19→15 domen z dnia na dzień) |
GEO i SEO nie są przeciwnikami. Schema, kondycja techniczna i głęboka, autorytatywna treść służą obu. Ale pomiar, jednostka treści i strategia off-site rozjeżdżają się mocno. A udawanie, że to to samo, to sposób, w jaki agencje sprzedają wczorajszy playbook po cenach z 2026.
6. Dlaczego ruch z AI wygląda na niewidzialny w analityce? Crawl-to-refer i niewidzialna publiczność
Oto dane, które tłumaczą, dlaczego „ruch z AI" wydaje się nie istnieć, choć twoja treść jest ewidentnie konsumowana. Silniki AI crawlują ogromnie, a odsyłają niemal nic.
Botify przeanalizował ~7 mld plików logów (listopad 2024 do marzec 2026) i ustalił, że OpenAI potroił crawl sieci od czasu GPT-5; aktywność GPTBota wzrosła 2,9×, delta +1,8 mld zdarzeń crawl. Zmienił się też balans między wyszukiwaniem a treningiem: stosunek zdarzeń wyszukiwania do treningowych wzrósł z ~0,95 do ~1,14. OpenAI wydaje teraz więcej budżetu na wyszukiwanie na żywo niż na zbieranie danych treningowych.
Brutalnym kontrapunktem jest crawl-to-refer, metryka rozpropagowana przez Cloudflare. Cloudflare Radar śledzi, jak często dana platforma AI crawluje stronę względem tego, ile odesłań do niej wysyła. Wskaźniki są ekstremalne i zmienne w czasie, własny snapshot Cloudflare z czerwca 2025 dawał Anthropic ~70 900:1; poniższe liczby za Q1 2026 (zestawione przez SEOmator z danych Cloudflare Radar) dotyczą już innego okresu:
| Bot | Stron scrawlowanych na 1 odesłanie (Q1 2026) |
|---|---|
| Anthropic ClaudeBot | 23 951 : 1 |
| OpenAI GPTBot | 1 276 : 1 |
| DuckDuckBot | ~1,5 : 1 |
| Googlebot | ~5 : 1 |
Te wskaźniki wahają się w zależności od okresu, a liczby odesłań prawdopodobnie zawyżają realną lukę (ruch z natywnych aplikacji, np. Claude, nie wysyła nagłówka Referer:, wg Cloudflare). Ale kierunek jest jednoznaczny. Rzędowo wysoki stosunek ClaudeBota to nie nieefektywność. To model biznesowy: czysty crawler treningowy bez konsumenckiej wyszukiwarki, która odsyłałaby użytkowników. Boty AI (GPTBot + ClaudeBot + Meta + Amazon + Petal) to dziś 51,69% całego ruchu crawlerów, więcej niż wszystkie tradycyjne crawlery wyszukiwarek razem wzięte. Sama Meta odpowiada za 36,10% ruchu crawl AI, przy zerowym odsyłaniu.
A nagroda za bycie cytowanym mimo wszystko? Ruch z odesłań AI, który jednak dociera, konwertuje na poziomie 4,4× wartości tradycyjnego ruchu organicznego (ConvertMate / Semrush 2026), przy 27% niższym bounce i 38% dłuższych sesjach. Mały wolumen, nieproporcjonalna wartość. Cała teza inwestycyjna GEO w jednym zdaniu.
7. Jak naprawdę mierzy się GEO? Na logu serwera, nie w dashboardzie
Tu stawiam granicę. Większość „narzędzi GEO" próbkuje wyjścia modeli, odpytując je wielokrotnie i licząc twoje wzmianki. To przydatne, ale to sonda, nie prawda gruntowa. Jedyne miejsce, by zobaczyć, co silniki AI naprawdę robią z twoją treścią, to twoje własne logi serwera.
To nie jest dla mnie nowe przekonanie. Analizą logów serwera zajmuję się od 2013 roku, to fundament porządnego technicznego SEO. Już wtedy z zespołem zbudowaliśmy własny pipeline analizy logów na Kibanie, zanim w ogóle powstały dedykowane narzędzia do logów crawlerów. Później prowadziłam analizy logów dla marketplace'ów takich jak Machineryzone, Agriaffaires i leboncoin oraz dla e-commerce expondo, sięgając po komercyjne platformy, w miarę jak ta kategoria dojrzewała. Z AI ta zasada się nie zmienia: każda migracja i każdy audyt, SEO czy GEO, powinien zaczynać się od analizy logów. GEO dokłada do logu tylko nowych aktorów. Dyscyplina czytania logu zostaje ta sama, która od ponad dekady oddziela prawdziwe techniczne SEO od zgadywania.
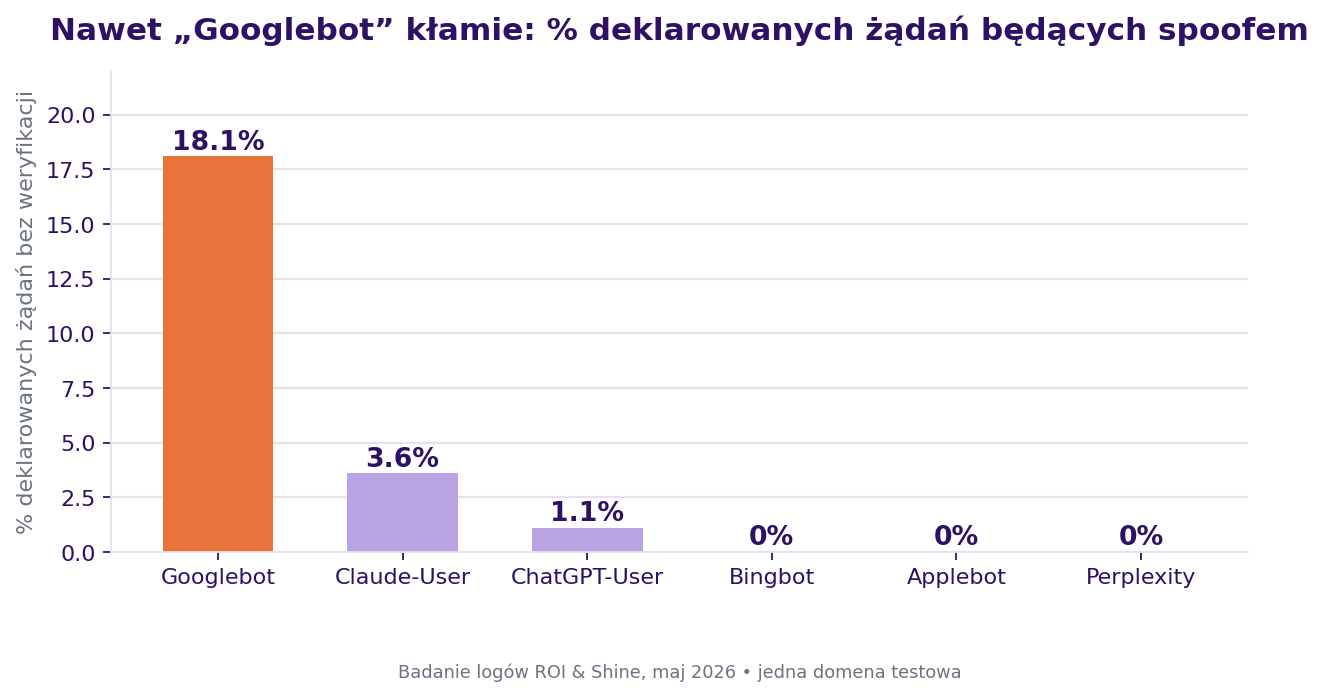
I oto, co te logi pokazują w praktyce. W badaniu, które przeprowadziliśmy w ROI & Shine na jednej z domen testowych (maj 2026, N=43 345 żądań w 26 dni, bez CDN z przodu, IP botów zweryfikowane względem opublikowanych zakresów i forward-confirmed reverse DNS), 4,3% całego deklarowanego ruchu botów nie przeszło weryfikacji. A 18% żądań podających się za Googlebota okazało się podszywaczami (68 IP bez poprawnego reverse DNS, w dużej części tani hosting w RU/UA/DE). Jeśli liczysz boty po user-agent, liczysz kłamców.
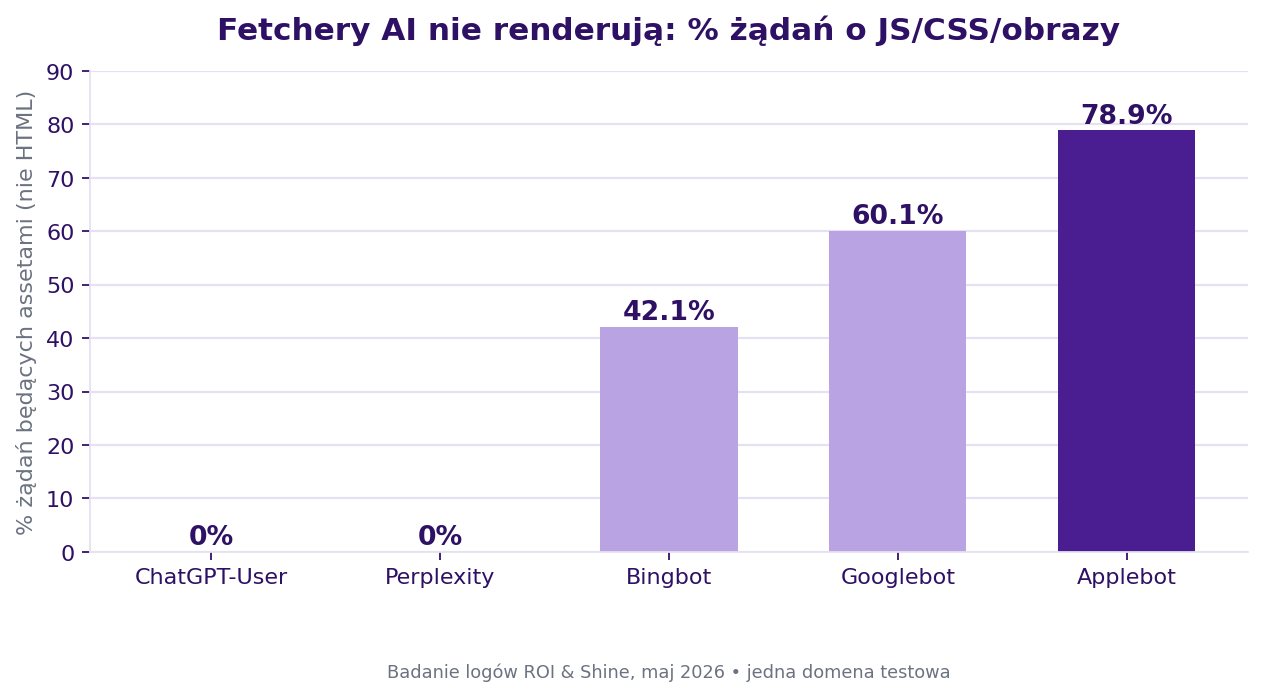
Te same logi obnażyły drugą twardą zasadę. Fetchery AI (ChatGPT-User, Perplexity) pobrały 0% assetów (JS/CSS/obrazy). Googlebot, 60%, a Applebot, 79%. Silniki AI nie renderowały JavaScriptu. Jeśli twoja treść zależy od JS po stronie klienta, fetcher nigdy jej nie zobaczy. Server-side HTML (SSR/SSG) to nie optymalizacja pod widoczność w AI. To warunek konieczny.
Pomiar GEO na poziomie logów odpowiada na pytania, których dashboardy nie udźwigną:
- Który bot i czy prawdziwy? Musisz oddzielić crawlery treningowe (GPTBot, ClaudeBot) od fetcherów real-time (ChatGPT-User, OAI-SearchBot, PerplexityBot), sygnalizują zupełnie inny intent. I musisz zweryfikować zakresy IP względem opublikowanych, żeby wyłapać podszywanie się: spora część ruchu podającego się w user-agent za „GPTBot" wcale nie pochodzi z OpenAI.
- Jaki jest twój własny crawl-to-refer? Benchmarki ogólne (23 951:1) to średnie. Realny stosunek twojej domeny, policzony z logów względem analityki odesłań AI, to jedyna liczba, która wycenia twój zwrot z GEO.
- Które strony są pobierane na żywo podczas generowania odpowiedzi? Trafienie fetchera real-time na URL, skorelowane z cytatem pojawiającym się w odpowiedzi, to najbliższe istniejące przybliżenie przyczynowego sygnału GEO.
Tego właśnie narzędzia oparte na sondach (Profound, Peec.ai, AthenaHQ) strukturalnie nie zrobią, siedzą poza twoim serwerem. Botify, Oncrawl i SEOmator zbudowały tę dyscyplinę dla plików logów; my stosujemy ją do atrybucji GEO.
Zapowiedź: pełne badanie, wkrótce. Liczby powyżej to pierwszy wycinek. ROI & Shine publikuje kompletne badanie logów (jedna z naszych domen): taksonomia botów, pełny rozkład podszywania się, luka renderowania i nasz prawdziwy crawl-to-refer. Pełna metodologia i wyniki w naszym hubie GEO i SEO. Jeśli twierdzenia o GEO nie da się wyśledzić do linii logu, traktuj je jak marketing.
8. Ostrzeżenie o samych cytatach: model może je zmyślać
Na koniec niedoceniane ryzyko, które oddziela poważne GEO od hype'u: silniki AI fabrykują cytaty w alarmującym tempie. Dwa świeże badania z 2026:
- GhostCite (arXiv 2602.06718) przebadał 13 czołowych modeli językowych w 40 dziedzinach. Halucynacje cytatów wahały się od 14,23% do 94,93%, zależnie od modelu i dziedziny.
- Badanie cross-model o ograniczeniach wdrożeniowych (arXiv 2603.07287) przetestowało 17 443 wygenerowane cytaty i ustaliło, że żaden model nie przekroczył wskaźnika istnienia cytatu 0,475. W najgorszych reżimach ponad połowa generowanych referencji wskazywała na nic.
Implikacja dla GEO jest ostra. Bycie wymienionym przez model i bycie poprawnie zaatrybuowanym z działającym linkiem to dwa różne wyniki. Mocne, jednoznaczne sygnały encyjne (spójne NAP, schema, brandowane wzmianki) zmniejszają szansę, że model przypisze twój fakt konkurencji, albo zmyślonemu źródłu.
Co to znaczy dla twojej strategii 2026
- Utrzymaj techniczne SEO (crawlability, schema, Core Web Vitals): to wspólny fundament obu płaszczyzn.
- Przesuń budżet off-site z surowego wolumenu linków na wzmianki o marce i earned media (sygnał 0,664).
- Pisz fragment-first: ekstrahowalne, samodzielne, atrybuowalne kawałki, które wygrywają pojedyncze podzapytania fan-out.
- Wypracuj obecność w źródłach społecznościowych (Reddit, fora), to dziś pełnoprawne cytaty AI.
- Mierz na serwerze, oddzielając typy botów i weryfikując IP, dashboard to sonda, log to prawda.
GEO to nie SEO z nowymi słowami kluczowymi. To inna płaszczyzna wyszukiwania, inna jednostka sukcesu i, co kluczowe, inny sposób pomiaru. Agencje, które rozumieją tę różnicę na poziomie logów, to te, które budują trwałą widoczność w AI.
Chcesz to wdrożyć? Zobacz usługi GEO i AEO ROI & Shine albo zgłęb temat w naszym hubie wiedzy GEO i SEO.