Every AI bot leaves a trail in your server logs. Which pages it grabs. Whether it runs your JavaScript. How rarely it sends a human back. That trail is the only ground truth about AI visibility there is. Everything else is a survey.
New to all this? Start with the explainer on the mechanism: GEO vs SEO: how AI search picks its sources.
Most GEO commentary never does what I did here. I took a freshly migrated domain, a brand-new test site with fresh content. I wired up the server logs on day one. Then I watched what the LLM bots actually got up to.
All of it before any dashboard could show a single citation.
The sample is small. That is the point. A new, small site is exactly the situation nobody bothers to measure. So the "zeros" I found are findings, not holes in the data.
They tell you two things. First, what the bulk-crawl machine flat-out ignores. Second, what fires the instant a real person asks a chatbot about you.
The sample, stated honestly: N = 43,345 HTTP requests over 26 days (3 to 29 May 2026), on one freshly migrated test domain, no CDN or proxy in front, 100% of log lines parsed. Bot IPs were verified against published OpenAI, Anthropic and Perplexity ranges. For Google, Bing and Apple I used FCrDNS, forward-confirmed reverse DNS, which matches the IP's name both ways. The limits are real, and I flag them throughout: a small single-domain sample, one month, no Google Search Console join.
Who ran this, and why logs?
I have been reading server logs since 2013, long before "AI crawler" was even a phrase. My SEO team and I built our own log-analysis pipeline on Kibana, back when no dedicated crawler-log tool existed yet. Since then I have read logs across marketplaces like Machineryzone, Agriaffaires and leboncoin, and e-commerce like expondo.
AI changed nothing about the rule. Every migration, every audit, starts with the log. GEO just adds new characters to the same access file. In twelve years of reading logs, the pattern that never changes is this: the log tells the truth, the dashboard tells a story. This study is mine, start to finish, methodology, parsing, verification.
So why do logs matter more in the AI era, not less? Survey-based GEO tools prompt the models again and again, then tally your mentions. That is useful. But it is a poll of what a model says.
The log is the only place you watch what a model does. Every fetch, every byte, every status code, tied to a verified IP. My rule of thumb is simple: if a GEO claim can't be traced back to a log line, treat it as marketing.
One European caveat sits underneath all of this. Server logs record IP addresses, and under EU law an IP is personal data. So responsible log work means pseudonymising early, retaining only briefly, and never exposing raw IPs in a report. That discipline is not a tax on the analysis, it is the analysis, because the same care that protects a visitor is the care that catches a spoofed bot.
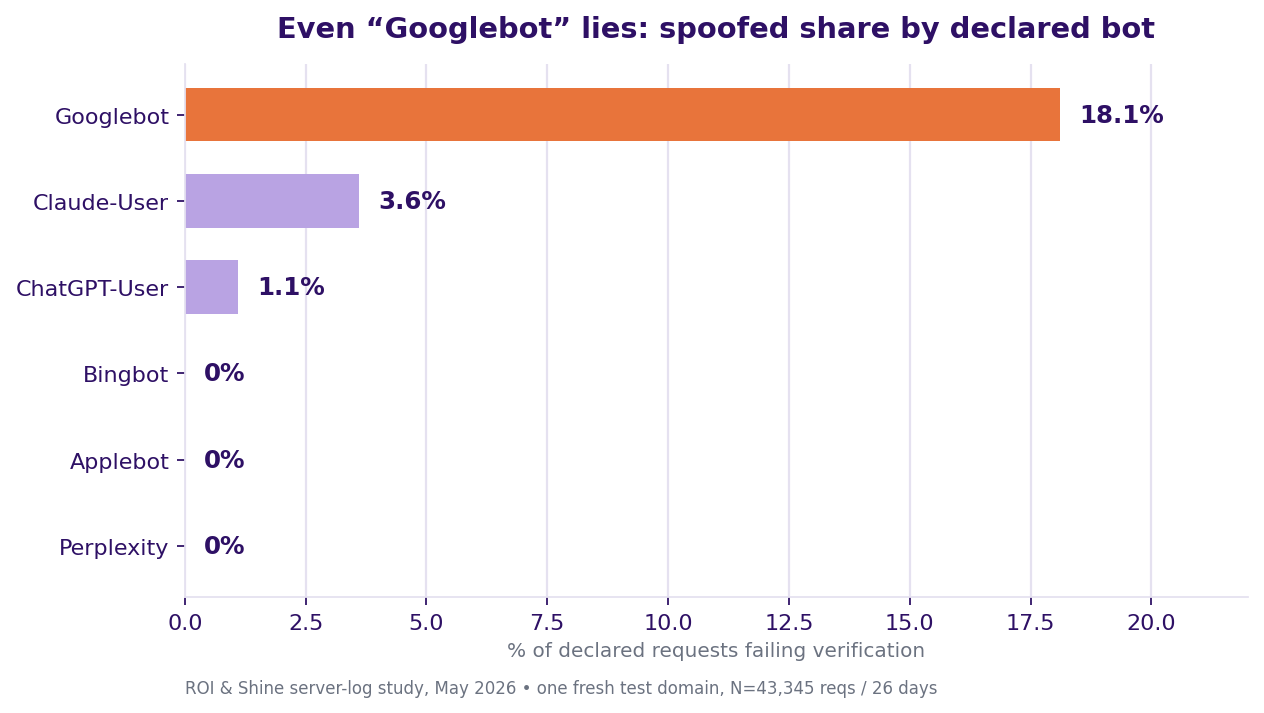
How much "bot traffic" is actually fake? 4.3% overall, 18% of Googlebot
Count bots by their user-agent and you are counting liars. Of 3,161 requests that claimed to be a known bot, 135 (4.3%) failed verification against published IP ranges and FCrDNS.
But the average hides the real story. The fakery didn't spread evenly. It piled up on the single most trusted name on the web.
| Declared bot | Spoof rate | Verified |
|---|---|---|
| Googlebot | 18.1% (100/554) | FCrDNS |
| Claude-User | 3.6% (31/852) | Anthropic CIDR |
| ChatGPT-User | 1.1% (4/356) | OpenAI CIDR |
| Bingbot, Applebot, Googlebot-Image, Perplexity | 0% | FCrDNS / CIDR |
Sixty-eight unique IPs pretended to be Googlebot. Fifty-nine had no reverse-DNS record at all. Nine resolved to hosts that were obviously not Google, colocationamerica.com, acedatacenter.com, amazonaws.com, pbiaas.com, scattered across cheap hosting in RU, UA and DE. Real Googlebot (52 IPs) always resolves to a googlebot.com or google.com PTR. No exceptions.
So what is really going on here? Spoofing is an authority-borrowing trick. Nobody bothers faking Applebot, there is no trust there worth stealing.
They fake Googlebot because thirty years of "just let Googlebot through" is baked into every firewall rule on the planet. I've seen this across a few migration cycles, and the target never moves: the impostors always cluster on the one name everyone waves through.
One caveat: this is an authenticity test, not an intent test. I can't tell you which fakers were SEO scrapers and which were malicious. And Google's published-range endpoint came back empty during my run. So FCrDNS, Google's own canonical method, was my sole way to verify Google and Bing.
Did the training crawlers show up? Not once
Here is the first deliberate zero. Across the entire month, GPTBot, ClaudeBot, CCBot, Bytespider, Google-Extended and Amazonbot made zero requests. Not one. And that is despite a robots.txt (Yoast-era WordPress) that left Disallow: empty, the door was wide open, training crawlers included.
A training crawler, to be clear, is a bot that collects pages to feed a model's training set. None of them came.
That contradicts the headlines in the big macro reports, and the contradiction is exactly the point. Botify, working from ~7 billion log files, reports that OpenAI tripled its web crawl since GPT-5, with GPTBot activity up 2.9×. True, at scale. But the same Botify data shows OpenAI's crawl is only ~4% of Google's volume (887M vs 18.2B events over 30 days).
And a freshly migrated small site sits below the threshold a bulk training crawler cares about entirely. The macro story says "AI is crawling everything, more than ever." The micro reality for a new domain is simpler. The training machine hasn't noticed you yet. Limitation: one month, no pre-migration baseline.
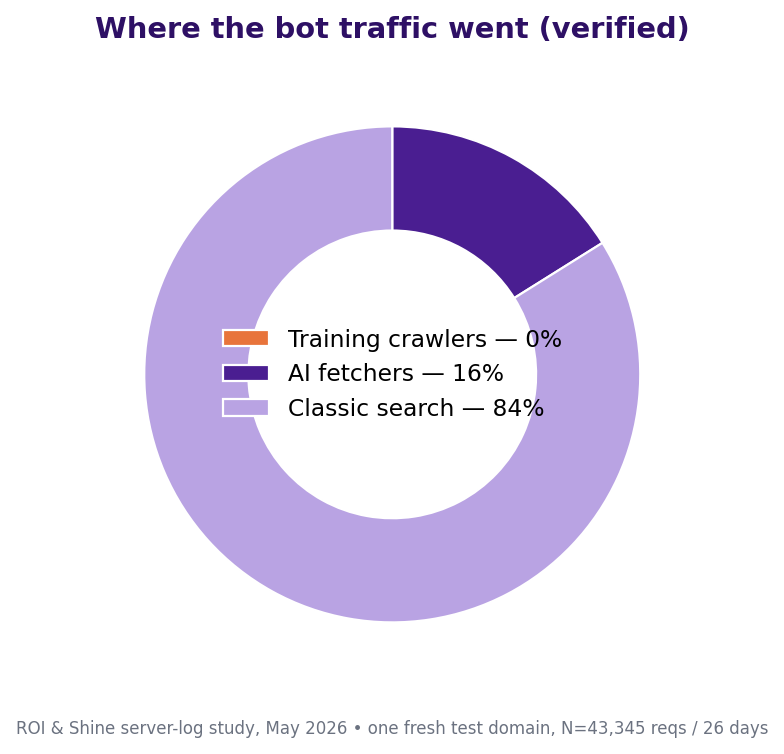
So which AI bots came, and how?
The AI presence was real, but lopsided. Here are the verified organic AI fetches:
| AI actor | Verified requests | Unique URLs | Note |
|---|---|---|---|
| ChatGPT-User | 352 | 45 | User-initiated fetch |
| Perplexity (User + Bot) | 4 | Marginal | |
| OAI-SearchBot | 0 | No bulk search crawl | |
| Claude (organic) | 0 | See MCP correction below |
Once again, this flips the macro trend on its head. Botify reports that OAI-SearchBot has already overtaken GPTBot globally, while ChatGPT-User fell 28% (Dec 2025 → Mar 2026). On my domain, OAI-SearchBot is zero and ChatGPT-User runs the show.
The reading is clean. A fresh small site gets user-initiated fetches, someone asks ChatGPT about a page, and the model goes off and reads it live. Not bulk SearchBot indexing.
That is a completely different world from a big, established publisher. And it tells you exactly where early AI visibility comes from: a human typing a prompt, not a crawl budget.
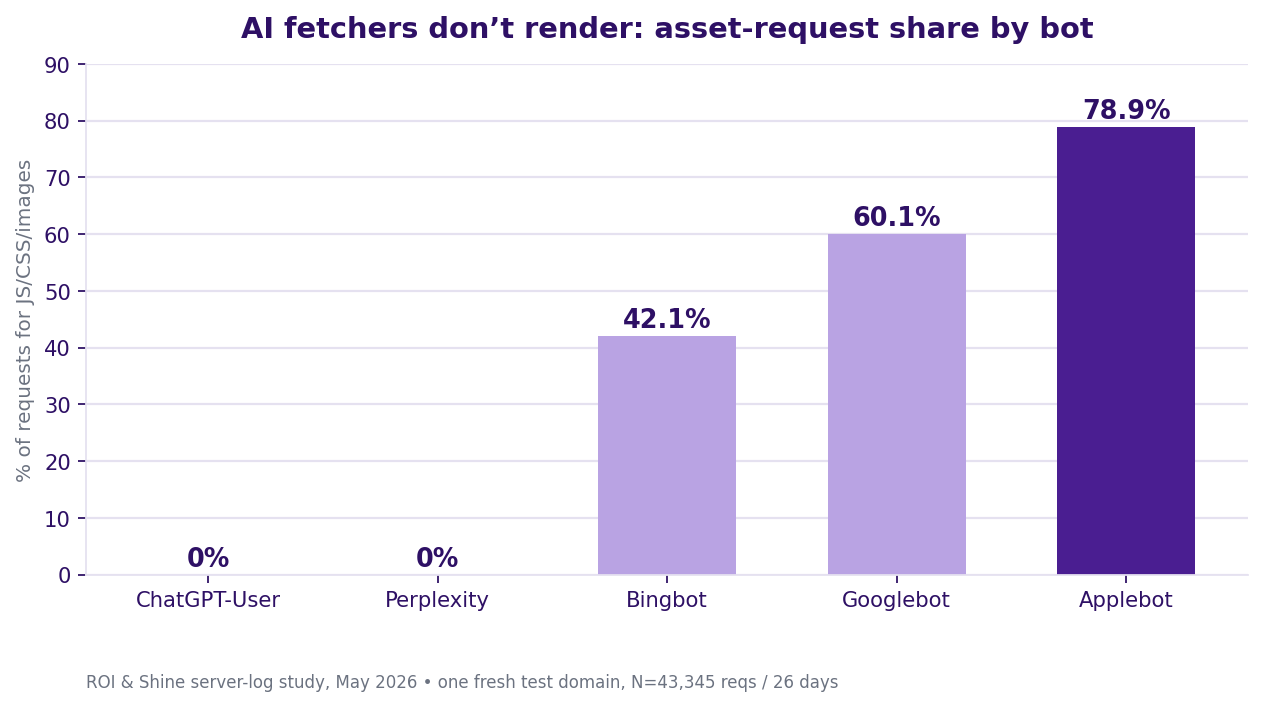
Do AI bots render JavaScript? No, they fetched 0% assets
This is the finding that matters most in practice, and it leaves no room for doubt. Here is the share of requests each bot made for assets, JS, CSS, images:
| Bot | Asset request share |
|---|---|
| ChatGPT-User | 0% |
| Perplexity | 0% |
| Bingbot | 42.1% |
| Googlebot | 60.1% |
| Applebot | 78.9% |
The AI fetchers pulled HTML and nothing else. No stylesheets, no scripts, no images. The classic search bots pulled assets the way any rendering engine has to.
So the conclusion writes itself. AI fetchers do not render, they do not run the page's JavaScript. A fetcher is a bot that pulls a page live to answer one question. If your content is injected client-side, the fetcher simply never sees it.
This isn't a nice-to-have. For AI visibility, your content has to live in server-side HTML, SSR or SSG. Full stop.
That is the whole reason moving off a JavaScript-dependent stack is a precondition for showing up in AI answers. It is not a performance tweak you get to later. Caveat: a missing asset request is strong but indirect evidence of non-rendering, a proxy, not a packet capture.
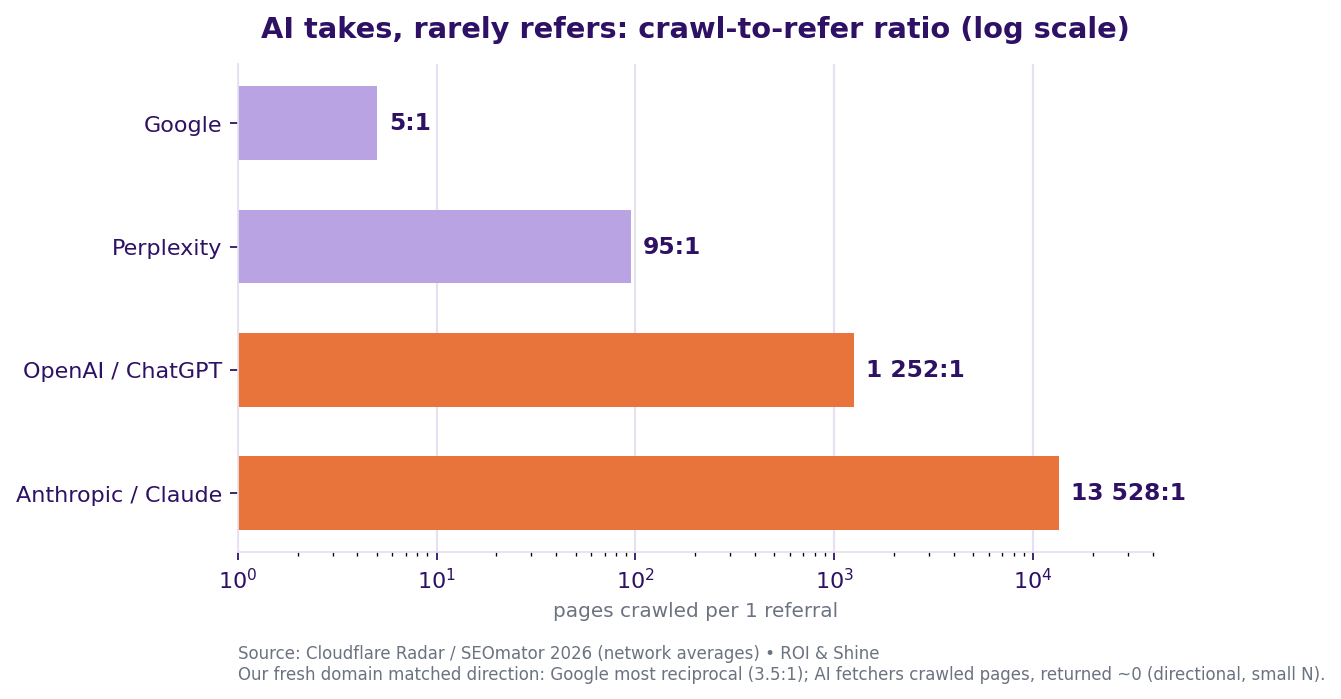
What is the real crawl-to-refer ratio? ChatGPT takes 352, sends 0
Crawl-to-refer means the pages a platform crawls for every human it sends back. It is the metric Cloudflare put on the map. Here is mine, as ratios, next to the global benchmarks.
| Platform | Our crawl : refer | Global benchmark (Cloudflare / SEOmator 2026) |
|---|---|---|
| OpenAI / ChatGPT | 352 : 0 (∞) | ~1,252 : 1 (was 785:1 → 1,851:1 → 1,252:1) |
| Apple | 869 : 0 (∞) | |
| Bing | 516 : 5 (103 : 1) | |
| 464 : 131 (3.5 : 1) | ~5 : 1 | |
| Perplexity | 4 : 1 (4 : 1) | ~95 : 1 |
| Anthropic / Claude | 0 organic : 33 (0 : 1) | ~13,528 : 1 (up to 20,583:1) |
Two readings, both honest. I confirm the direction. AI takes a lot and gives almost nothing back. Google is the only one playing roughly fair, my 3.5:1 actually beats the global ~5:1 baseline. That same pattern Cloudflare and SEOmator see across the whole network shows up again on a single fresh domain.
But I contradict the Anthropic figure, and the reason is the catch I unpack just below. Globally, Anthropic is the most extractive bot on record (~13,528:1). On my domain it shows zero organic crawl and 33 referrals (0:1), seemingly the most reciprocal of the lot.
That flip is an artifact, not a triumph. Pulling it apart is where the real rigor lives. Caveat: referer counts run low because AI platforms strip the header, the referral N is tiny, and there's no GSC join, so read these ratios as directional, not precise.
The correction: a "Claude surge" that was me
By raw user-agent, Claude-User looked like the runaway leader of AI traffic, 852 requests, roughly 4× ChatGPT-User. It would have made a great headline. It was also completely wrong.
821 of those 852 requests were POSTs to /wp-json/stifli-flex-mcp/v1/messages. That is the endpoint of a WordPress plugin's MCP server, hit from 5 IPs inside Anthropic's egress range (160.79.104.0/21). Those are Model Context Protocol calls, first-party automation, not visibility crawls. In plain terms: my own tooling talking to my own site.
Strip them out and Claude's organic AI visibility is zero. That lines up with my GEO tracker baseline of 0/30 mentions.
Without that separation, every number downstream would have been poisoned, the crawl-to-refer table, the "AI traffic leader" crown, all of it. This is precisely the correction a survey tool can't make, and most log dashboards never make. They count the POSTs as Anthropic and move on. Assumption: this is owner traffic, overwhelmingly likely, given the narrow 5-IP range and the relentless POST pattern.
What about the heavy lifters, Bing and the asset hogs?
Two more findings worth a practitioner's attention, both from my own logs.
- Bing pulled 117.9 MB, 3× more data than every other bot combined. Bing was 73% of all bot transfer on just 23% of requests. Googlebot is the mirror image: many requests, few bytes, lean and HEAD-driven. Applebot 29.5 MB, ChatGPT-User 10.4 MB, Googlebot 3.5 MB.
- Bingbot covered the site most widely, 290 unique URLs, roughly 2× Googlebot's 99. Applebot 119, ChatGPT-User 45. On a small fresh domain, Bing crawls broadest. That runs against Google's reputation for volume dominance. Caveat: breadth is not index quality.
And on safety, the picture was calm. Zero verified-bot hits on sensitive paths, no wp-login.php, no xmlrpc.php, nothing in wp-admin beyond admin-ajax. The lone exception was Googlebot hitting /wp-json/complianz once, a cookie-consent API.
The site was wide open: allow-all robots.txt, no AI directives. So formally there were zero violations, but also zero protection against training crawlers.
That shapes a deliberate call on the new stack. The post-migration robots.txt should consciously pick its stance on GPTBot, CCBot and Google-Extended, training opt-in or opt-out. It should not inherit an empty Disallow: by accident.
The bigger context: the citation space is tightening
For a fresh domain, the macro trend matters a lot. Resoneo's measurement (via Dataconomy) tracked how ChatGPT sourced its answers after the GPT-5.3 Instant transition. The average number of domains cited per response fell ~20% (19 → 15), and URLs from 24 → 19, across 27,000 responses (400 prompts/day over 14 weeks). My ChatGPT-User crawled shallow too, just 45 unique URLs. That fits the "fewer sites, but deeper" picture.
There is a European layer here as well. These citation patterns are measured mostly on English prompts. But the markets I work in, Polish, German, French, each have their own thinner citation pool, where a single trusted source carries far more weight. On a multilingual web, being the cited domain in your own language is its own kind of moat.
For a freshly migrated domain sitting at a GEO baseline of 0/30, that is a rising wall to climb. The citation pipeline is squeezing onto fewer trusted domains at the exact moment you're trying to get in. This is correlation, not causation, but the direction is clear enough. Earn entity trust early, and earn it hard.
What this study means for your 2026 setup
- Verify bots by IP, never by user-agent. Up to 18% of your "Googlebot" could be impostors.
- Ship server-side HTML. AI fetchers don't render JavaScript. SSR/SSG is the price of AI visibility, not an upgrade.
- Compute your own crawl-to-refer ratio from your own logs. The 13,528:1 benchmarks are network averages, not your number.
- Quarantine your own automation, MCP, monitoring, internal tools, before you measure anything. Otherwise you count yourself as a bot.
- Decide your robots.txt stance on purpose. Allow-all by inheritance is a non-decision on your training data.
- Treat IPs as personal data. Pseudonymise, retain briefly, never publish raw addresses. Under EU law it is required, and it makes the analysis sharper, not slower.
The macro reports are right about the network. They just stay silent about the world a new, small site actually lives in. And that world shows up in one place only: your own logs.
Want this run on your own domain? See ROI & Shine's GEO and SEO services, or dig deeper in our GEO & SEO knowledge hub. The companion piece on the mechanism: GEO vs SEO: how AI search picks its sources.