Każdy bot AI zostawia w logach serwera ślad. Które strony pobiera. Czy wykonuje twój JavaScript. Jak rzadko odsyła człowieka z powrotem. Ten ślad to jedyny twardy pomiar widoczności w AI, jaki istnieje. Cała reszta to ankieta.
Pierwszy raz przy tym temacie? Zacznij od wyjaśnienia mechanizmu: GEO vs SEO: jak AI wybiera źródła.
Większość treści o GEO nigdy nie robi tego, co zrobiłam tutaj. Wzięłam świeżo zmigrowaną domenę, nową witrynę testową z nowym kontentem. Podpięłam logi serwera od pierwszego dnia. I patrzyłam, co boty LLM naprawdę robią.
A wszystko to, zanim jakikolwiek dashboard pokazał choćby jedno cytowanie.
Próba jest mała. I o to właśnie chodzi. Nowa, mała witryna to dokładnie ten przypadek, którego nikt nie mierzy. Dlatego „zera", które znalazłam, to wyniki, nie braki w danych.
Mówią dwie rzeczy. Pierwsza: co maszyna masowego crawlu (bulk crawl, hurtowe pobieranie stron do bazy) po prostu ignoruje. Druga: co odpala się w sekundzie, gdy żywy człowiek pyta chatbota o ciebie.
Próba, uczciwie: N = 43 345 żądań HTTP w 26 dni (3 do 29 maja 2026), jedna świeżo zmigrowana domena testowa, bez CDN i proxy z przodu, 100% sparsowanych linii logu. IP botów sprawdzone wobec opublikowanych zakresów OpenAI/Anthropic/Perplexity oraz przez forward-confirmed reverse DNS (dwukierunkowe potwierdzenie nazwy i adresu IP) dla Google/Bing/Apple. Ograniczenia są realne i zaznaczam je w tekście: mała próba z jednej domeny, jeden miesiąc, brak połączenia z Google Search Console.
Kto to przeprowadził i dlaczego akurat logi?
Logi serwera czytam od 2013 roku, na długo, zanim „crawler AI" stał się w ogóle pojęciem. Z moim zespołem SEO zbudowaliśmy własny system analizy logów na Kibanie, gdy nie istniało jeszcze żadne gotowe narzędzie do tego zadania. Później czytałam logi na takich marketplace'ach jak Machineryzone, Agriaffaires i leboncoin oraz w e-commerce typu expondo.
AI nie zmieniło tu jednej reguły. Każda migracja, każdy audyt zaczyna się od logu. GEO dokłada tylko nowych aktorów do tego samego pliku dostępu. Przez dwanaście lat czytania logów wzorzec, który się nie zmienia, jest jeden: log mówi prawdę, dashboard opowiada historię. To badanie jest moje, od początku do końca, metodologia, parsowanie, weryfikacja.
Dlaczego więc w erze AI logi liczą się bardziej, nie mniej? Narzędzia GEO oparte na ankiecie wielokrotnie odpytują modele i zliczają twoje wzmianki. To przydatne. Ale to sondaż tego, co model mówi.
Log to jedyne miejsce, gdzie widać, co model robi. Każde pobranie, każdy bajt, każdy kod statusu, przypisany do zweryfikowanego IP. Moja zasada jest prosta: jeśli tezy o GEO nie da się prześledzić do konkretnej linijki logu, potraktuj ją jak marketing.
Pod tym wszystkim leży jedno europejskie zastrzeżenie. Logi zapisują adresy IP, a w świetle prawa UE adres IP to dane osobowe. Odpowiedzialna praca z logami oznacza więc: pseudonimizuj wcześnie, trzymaj krótko, nigdy nie pokazuj surowych IP w raporcie. Ta dyscyplina nie jest podatkiem od analizy, ona jest analizą. Bo ta sama staranność, która chroni odwiedzającego, łapie podszywacza.
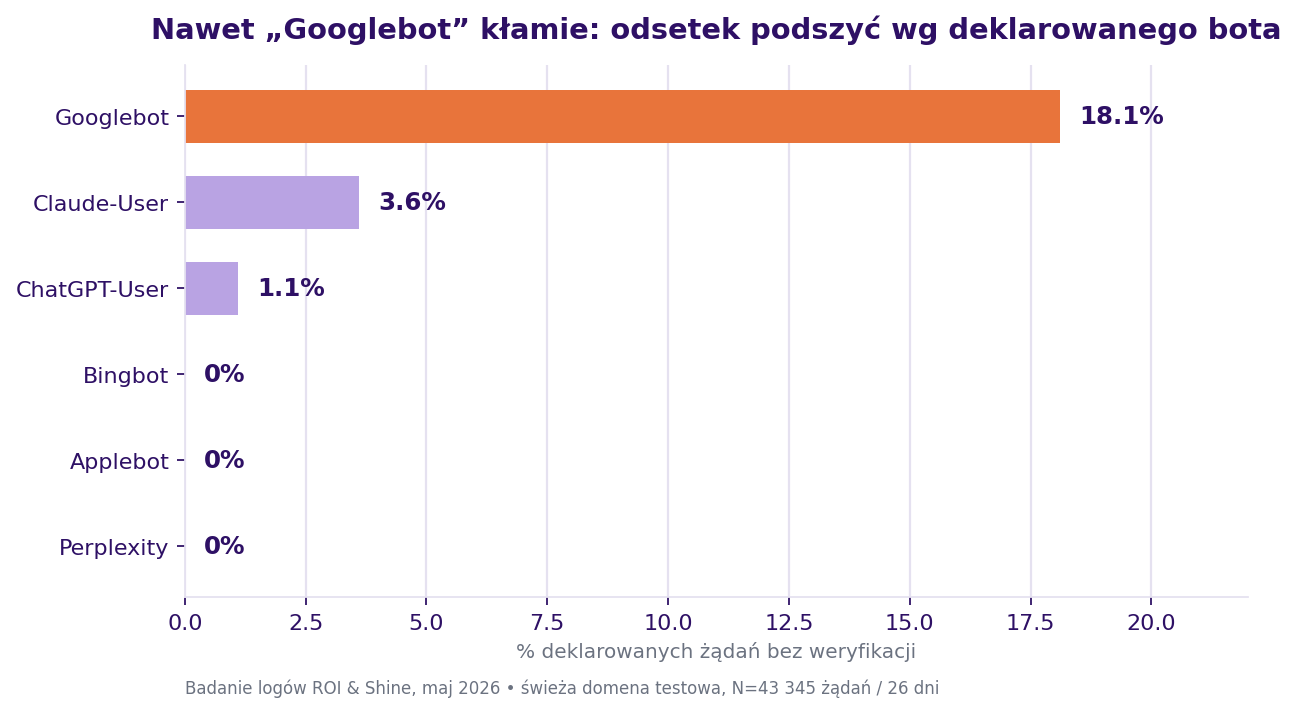
Ile „ruchu botów" jest fałszywe? 4,3% ogółem, 18% Googlebota
Jeśli liczysz boty po user-agencie (etykiecie, którą bot sam o sobie podaje), liczysz kłamców. Z 3 161 żądań, które zadeklarowały się jako znany bot, 135 (4,3%) nie przeszło weryfikacji wobec opublikowanych zakresów IP i forward-confirmed reverse DNS.
Ale średnia ukrywa prawdziwą historię. Podszywanie się nie rozłożyło się równo. Skupiło się na jednej, najbardziej zaufanej nazwie w sieci:
| Deklarowany bot | Odsetek podszyć | Weryfikacja |
|---|---|---|
| Googlebot | 18,1% (100/554) | FCrDNS |
| Claude-User | 3,6% (31/852) | CIDR Anthropic |
| ChatGPT-User | 1,1% (4/356) | CIDR OpenAI |
| Bingbot, Applebot, Googlebot-Image, Perplexity | 0% | FCrDNS / CIDR |
Pod Googlebota podszywało się 68 różnych adresów IP. Pięćdziesiąt dziewięć z nich nie miało żadnego rekordu reverse DNS. Dziewięć rozwiązywało się do hostów, które z Google nie mają nic wspólnego, colocationamerica.com, acedatacenter.com, amazonaws.com, pbiaas.com, porozrzucanych po tanim hostingu w Rosji, Ukrainie i Niemczech. Prawdziwy Googlebot (52 IP) zawsze rozwiązuje się do nazwy kończącej się na googlebot.com lub google.com. Bez wyjątków.
Co tu się więc naprawdę dzieje? Podszywanie się to sztuczka na pożyczonym autorytecie. Nikt nie zadaje sobie trudu, by udawać Applebota, nie ma tam zaufania, które warto by ukraść.
Udają Googlebota, bo trzydzieści lat zasady „po prostu przepuść Googlebota" jest wpisane w każdą regułę firewalla na świecie. Widziałam to przez kilka cykli migracji i cel nigdy się nie przesuwa: podszywacze zawsze gromadzą się wokół tej jednej nazwy, którą wszyscy machają ręką.
Jedno zastrzeżenie: to test prawdziwości, nie intencji. Nie powiem ci, którzy podszywacze byli scraperami konkurencji SEO, a którzy działali złośliwie. Endpoint z opublikowanym zakresem IP Google podczas mojego biegu zwracał pustkę. Dlatego forward-confirmed reverse DNS, własna, kanoniczna metoda Google, był moją jedyną weryfikacją dla Google i Binga.
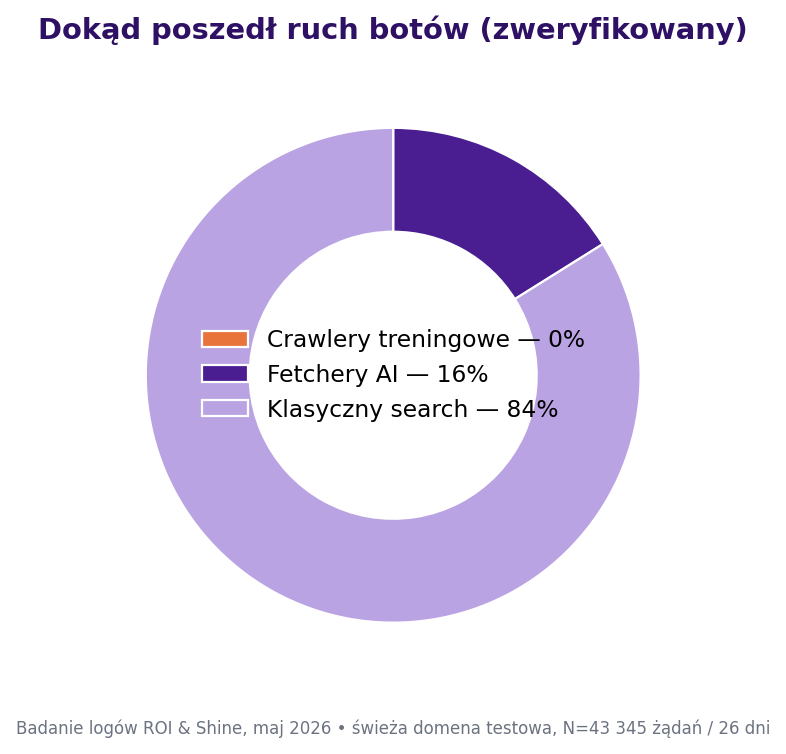
Czy crawlery treningowe się pojawiły? Ani razu
To pierwsze celowe „zero". Przez cały miesiąc GPTBot, ClaudeBot, CCBot, Bytespider, Google-Extended i Amazonbot wykonały zero żądań. Ani jednego. A robots.txt (z czasów WordPressa z Yoastem) miał pustą dyrektywę Disallow:, drzwi stały otworem na oścież, także dla crawlerów treningowych.
Crawler treningowy, dla jasności, to bot, który zbiera strony, by zasilić zbiór treningowy modelu. Żaden z nich nie przyszedł.
To przeczy nagłówkom z głównych raportów makro. I właśnie ta sprzeczność jest wynikiem. Botify, analizując ~7 mld plików logów, raportuje, że crawl OpenAI potroił się od premiery GPT-5, a aktywność GPTBota wzrosła 2,9×. W skali całej sieci, prawda. Ale te same dane Botify pokazują, że crawl OpenAI to ledwie ~4% wolumenu Google (887 mln vs 18,2 mld zdarzeń na 30 dni).
A świeżo zmigrowana mała witryna jest poniżej progu, którym masowy crawler treningowy w ogóle się przejmuje. Wersja makro brzmi: „AI crawluje wszystko, mocniej niż kiedykolwiek". Mikro-rzeczywistość nowej domeny jest prostsza. Maszyna treningowa jeszcze cię nie zauważyła. Ograniczenie: jeden miesiąc, brak punktu odniesienia sprzed migracji.
Które więc boty AI przyszły, i w jakim trybie?
Boty AI faktycznie się pojawiły, ale nierówno. Zweryfikowane, organiczne pobrania AI:
| Aktor AI | Zweryfikowane żądania | Unikalne URL | Uwaga |
|---|---|---|---|
| ChatGPT-User | 352 | 45 | Pobranie wywołane przez użytkownika |
| Perplexity (User + Bot) | 4 | Marginalne | |
| OAI-SearchBot | 0 | Brak masowego crawlu wyszukiwania | |
| Claude (organicznie) | 0 | Patrz korekta MCP niżej |
To znów wywraca trend makro do góry nogami. Botify raportuje, że OAI-SearchBot globalnie wyprzedził już GPTBota, a ruch ChatGPT-User spadł o 28% (XII 2025 → III 2026). Na mojej domenie OAI-SearchBot to zero, a ChatGPT-User rozdaje karty.
Odczyt jest czysty. Świeża, mała witryna dostaje pobrania wywołane przez użytkownika, ktoś pyta ChatGPT o stronę, a model idzie i czyta ją na żywo. Nie ma za to masowego indeksowania przez SearchBota.
To zupełnie inny świat niż u dużego, ugruntowanego wydawcy. I mówi dokładnie, skąd bierze się wczesna widoczność w AI: z człowieka wpisującego pytanie, nie z budżetu crawlu.
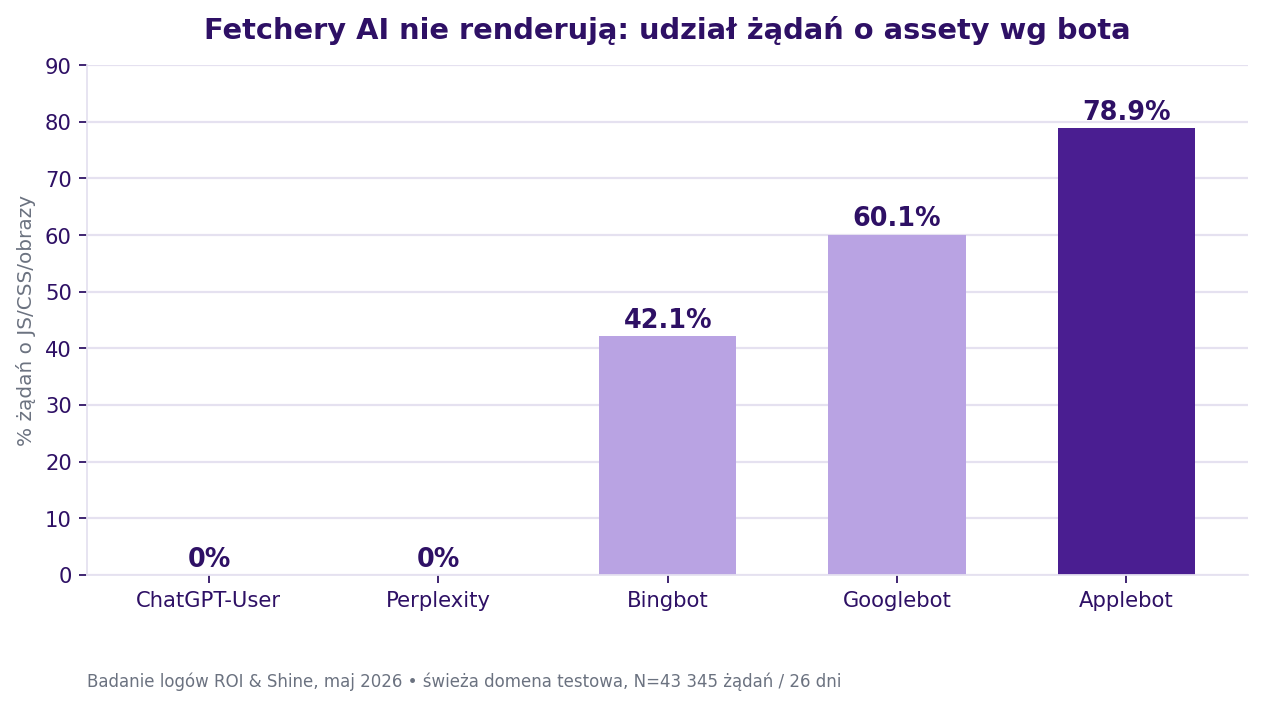
Czy boty AI renderują JavaScript? Nie, pobrały 0% assetów
To najważniejszy wynik w praktyce, i jednoznaczny. Udział żądań o assety (pliki JS, CSS, obrazy) w podziale na boty:
| Bot | Udział żądań o assety |
|---|---|
| ChatGPT-User | 0% |
| Perplexity | 0% |
| Bingbot | 42,1% |
| Googlebot | 60,1% |
| Applebot | 78,9% |
Fetchery AI pobrały HTML i nic więcej. Żadnych arkuszy stylów, żadnych skryptów, żadnych obrazów. Klasyczne boty wyszukiwarek pobierały assety tak, jak musi to robić każdy silnik renderujący stronę.
Wniosek pisze się więc sam. Fetchery AI nie renderują, nie wykonują JavaScriptu strony. Fetcher to bot, który pobiera stronę na żywo, by odpowiedzieć na jedno pytanie. Jeśli twoja treść doczytuje się dopiero po stronie przeglądarki, fetcher po prostu nigdy jej nie zobaczy.
To nie jest „miło mieć". Dla widoczności w AI treść musi być w HTML gotowym po stronie serwera, SSR albo SSG. Kropka.
I to jest cały powód, dla którego zejście ze stosu zależnego od JS to warunek konieczny pojawienia się w odpowiedziach AI. Nie kosmetyka pod kątem szybkości, którą można zrobić później. Zastrzeżenie: brak żądań o assety to mocny, ale pośredni dowód braku renderowania, sygnał zastępczy, nie podsłuch ruchu sieciowego.
Jaki jest realny crawl-to-refer? ChatGPT bierze 352, odsyła 0
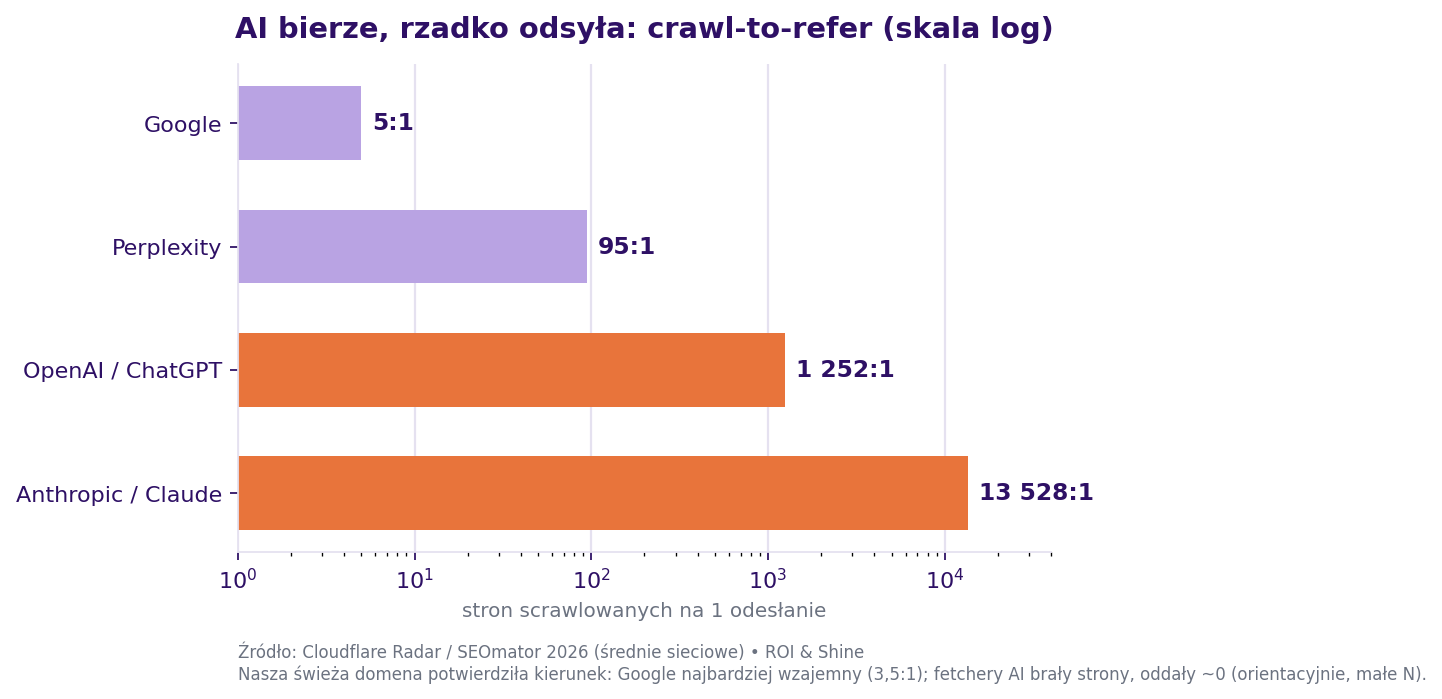
Crawl-to-refer to liczba stron, które platforma pobiera na jednego odesłanego z powrotem człowieka. To metryka, którą do obiegu wprowadził Cloudflare. Oto moja, jako proporcja, obok globalnych punktów odniesienia:
| Platforma | Nasz crawl : refer | Benchmark globalny (Cloudflare / SEOmator 2026) |
|---|---|---|
| OpenAI / ChatGPT | 352 : 0 (∞) | ~1 252 : 1 (było 785:1 → 1 851:1 → 1 252:1) |
| Apple | 869 : 0 (∞) | |
| Bing | 516 : 5 (103 : 1) | |
| 464 : 131 (3,5 : 1) | ~5 : 1 | |
| Perplexity | 4 : 1 (4 : 1) | ~95 : 1 |
| Anthropic / Claude | 0 organicznie : 33 (0 : 1) | ~13 528 : 1 (do 20 583:1) |
Dwa odczyty, oba uczciwe. Kierunek potwierdzam. AI bierze ogromnie dużo i oddaje niemal nic. Tylko Google gra mniej więcej fair, moje 3,5:1 jest nawet lepsze niż globalny punkt odniesienia ~5:1. Ten sam wzorzec, który Cloudflare i SEOmator widzą w całej sieci, odtworzył się na jednej świeżej domenie.
Ale liczbie Anthropic przeczę, a powód to korekta, którą rozplątuję tuż niżej. Globalnie Anthropic to najbardziej zachłanny bot w historii pomiarów (~13 528:1). Na mojej domenie pokazuje zero organicznego crawlu i 33 odesłania (0:1), pozornie najbardziej wzajemny ze wszystkich.
To odwrócenie jest artefaktem, nie triumfem. I właśnie w jego rozplątaniu kryje się cały rygor. Zastrzeżenie: liczby odesłań są zaniżone, bo platformy AI usuwają nagłówek Referer:, samych odesłań jest bardzo mało, a nie mam połączenia z Google Search Console, te proporcje są orientacyjne, nie precyzyjne.
Korekta: „skok Claude", którym byliśmy my sami
Sądząc po samym user-agencie, Claude-User wyglądał na zdecydowanego lidera ruchu AI, 852 żądania, jakieś 4× tyle co ChatGPT-User. Byłby z tego świetny nagłówek. Był też całkowicie błędny.
821 z tych 852 żądań to POST-y na adres /wp-json/stifli-flex-mcp/v1/messages. To endpoint serwera MCP we wtyczce WordPressa, odpytywany z 5 adresów IP z zakresu wyjściowego Anthropic (160.79.104.0/21). To wywołania protokołu Model Context Protocol, moja własna automatyzacja, nie crawl pod widoczność. Mówiąc wprost: moje narzędzie rozmawiało z moją stroną.
Po ich odsianiu organiczna widoczność Claude wynosi zero. Zgadza się to z punktem wyjścia mojego trackera GEO, 0/30 wzmianek.
Gdybym tego nie rozdzieliła, każda kolejna metryka byłaby skażona, tabela crawl-to-refer, tytuł „lidera ruchu AI", wszystko. To dokładnie ten typ korekty, którego narzędzie ankietowe zrobić nie potrafi, a większość dashboardów logów nigdy nie robi. Liczą POST-y jako Anthropic i jadą dalej. Założenie: to ruch właściciela, w przeważającej mierze prawdopodobne przy wąskim zakresie 5 IP i nieustannym wzorcu POST.
A „ciężki kaliber", Bing i pożeracze assetów?
Dwa kolejne wyniki warte uwagi praktyka, oba z moich własnych danych.
- Bing pobrał 117,9 MB, 3× więcej transferu niż wszystkie pozostałe boty razem. Bing to 73% całego transferu botów przy zaledwie 23% żądań. Googlebot działa na odwrót: dużo żądań, mało bajtów, oszczędny i oparty na metodzie HEAD. Applebot 29,5 MB, ChatGPT-User 10,4 MB, Googlebot 3,5 MB.
- To Bingbot pokrył witrynę najszerzej, 290 unikalnych adresów URL, około 2× tyle co Googlebot (99). Applebot 119, ChatGPT-User 45. Na małej, świeżej domenie to Bing crawluje najszerzej. A to przeczy reputacji Google jako lidera wolumenu. Zastrzeżenie: szerokość crawlu to nie to samo co jakość indeksacji.
A o bezpieczeństwie, obraz był spokojny. Zero trafień zweryfikowanych botów w ścieżki wrażliwe, żadnego wp-login.php, żadnego xmlrpc.php, nic w wp-admin poza admin-ajax. Jedyny wyjątek to Googlebot, który raz trafił w /wp-json/complianz, czyli API zgód na cookies.
Witryna była całkowicie otwarta: robots.txt „pozwól na wszystko", bez dyrektyw dla AI. Formalnie więc zero naruszeń, ale też zero ochrony przed crawlerami treningowymi.
I stąd świadoma decyzja na nowym stosie. Po migracji robots.txt powinien celowo zająć stanowisko wobec GPTBot, CCBot i Google-Extended, zgoda czy odmowa na trening. Nie powinien przez przypadek dziedziczyć pustej dyrektywy Disallow:.
Szerszy kontekst: pole cytowań się zagęszcza
Dla świeżej domeny trend makro ma znaczenie. Pomiar Resoneo (za Dataconomy) pokazał, jak zmieniło się cytowanie źródeł przez ChatGPT po przejściu na GPT-5.3 Instant. Średnia liczba domen cytowanych na jedną odpowiedź spadła o ~20% (z 19 do 15), a adresów URL, z 24 do 19. Zmierzono to na 27 000 odpowiedzi (400 promptów dziennie × 14 tygodni). Mój ChatGPT-User crawlował płytko, raptem 45 unikalnych URL-i. Pasuje to do schematu „mniej witryn, ale głębiej".
Jest tu też warstwa europejska. Te wzorce cytowań mierzy się głównie na promptach po angielsku. Ale rynki, na których pracuję, polski, niemiecki, francuski, mają każdy własną, płytszą pulę cytowań. Tam pojedyncze zaufane źródło waży nieporównanie więcej. W wielojęzycznej sieci bycie tą cytowaną domeną we własnym języku to osobny rodzaj fosy.
Dla świeżo zmigrowanej domeny przy starcie GEO 0/30 to rosnąca bariera wejścia. Pole cytowań zagęszcza się na coraz mniejszej liczbie zaufanych domen, dokładnie wtedy, gdy próbujesz się do niego wbić. To korelacja, nie przyczyna, ale kierunek jest dość jasny: buduj zaufanie do swojej marki jako encji wcześnie i ostro.
Co to badanie oznacza dla twojej konfiguracji w 2026
- Weryfikuj boty po IP, nigdy po user-agencie. Nawet 18% twojego „Googlebota" może być oszustami.
- Podawaj HTML gotowy po stronie serwera. Fetchery AI nie renderują JavaScriptu. SSR/SSG to warunek konieczny widoczności w AI, nie upgrade.
- Policz swój crawl-to-refer z własnych logów. Punkty odniesienia rzędu 13 528:1 to średnie sieciowe, nie twoja liczba.
- Odetnij własną automatyzację, MCP, monitoring, narzędzia wewnętrzne, zanim cokolwiek zmierzysz. Inaczej policzysz samego siebie jako bota.
- Świadomie zdecyduj o robots.txt. „Pozwól na wszystko" z rozpędu to brak decyzji o twoich danych treningowych.
- Traktuj IP jako dane osobowe. Pseudonimizuj, trzymaj krótko, nigdy nie publikuj surowych adresów. W świetle prawa UE to obowiązek, i wyostrza analizę, a nie spowalnia.
Raporty makro mają rację co do całej sieci. Milczą za to o świecie, w którym naprawdę żyje nowa, mała witryna. A ten świat widać tylko w jednym miejscu: w twoich własnych logach.
Chcesz to odpalić na swojej domenie? Zobacz usługi GEO i SEO ROI & Shine albo wejdź głębiej w nasz hub wiedzy GEO & SEO. Towarzysz na poziomie mechanizmu: GEO vs SEO: jak AI wybiera źródła.